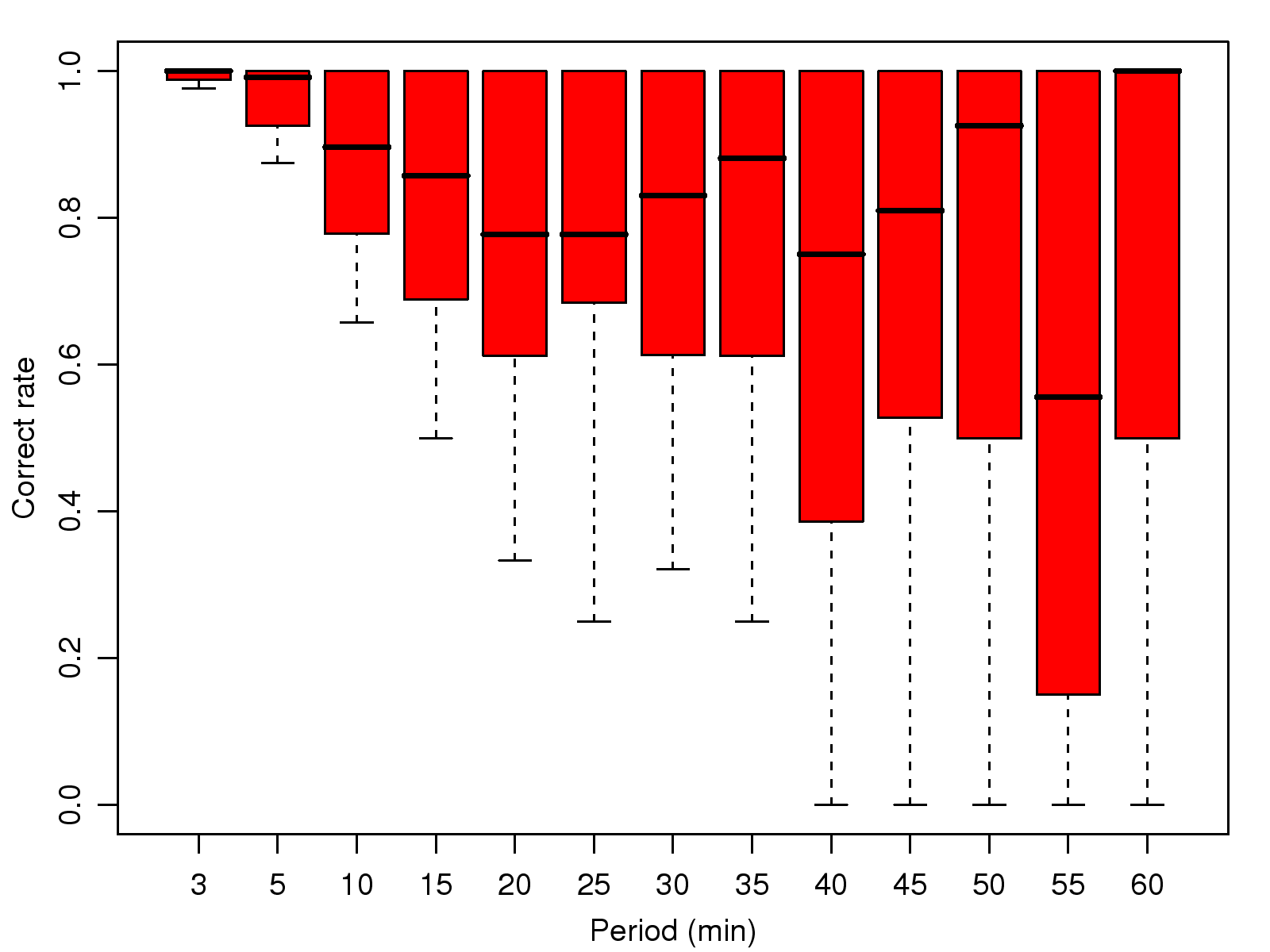
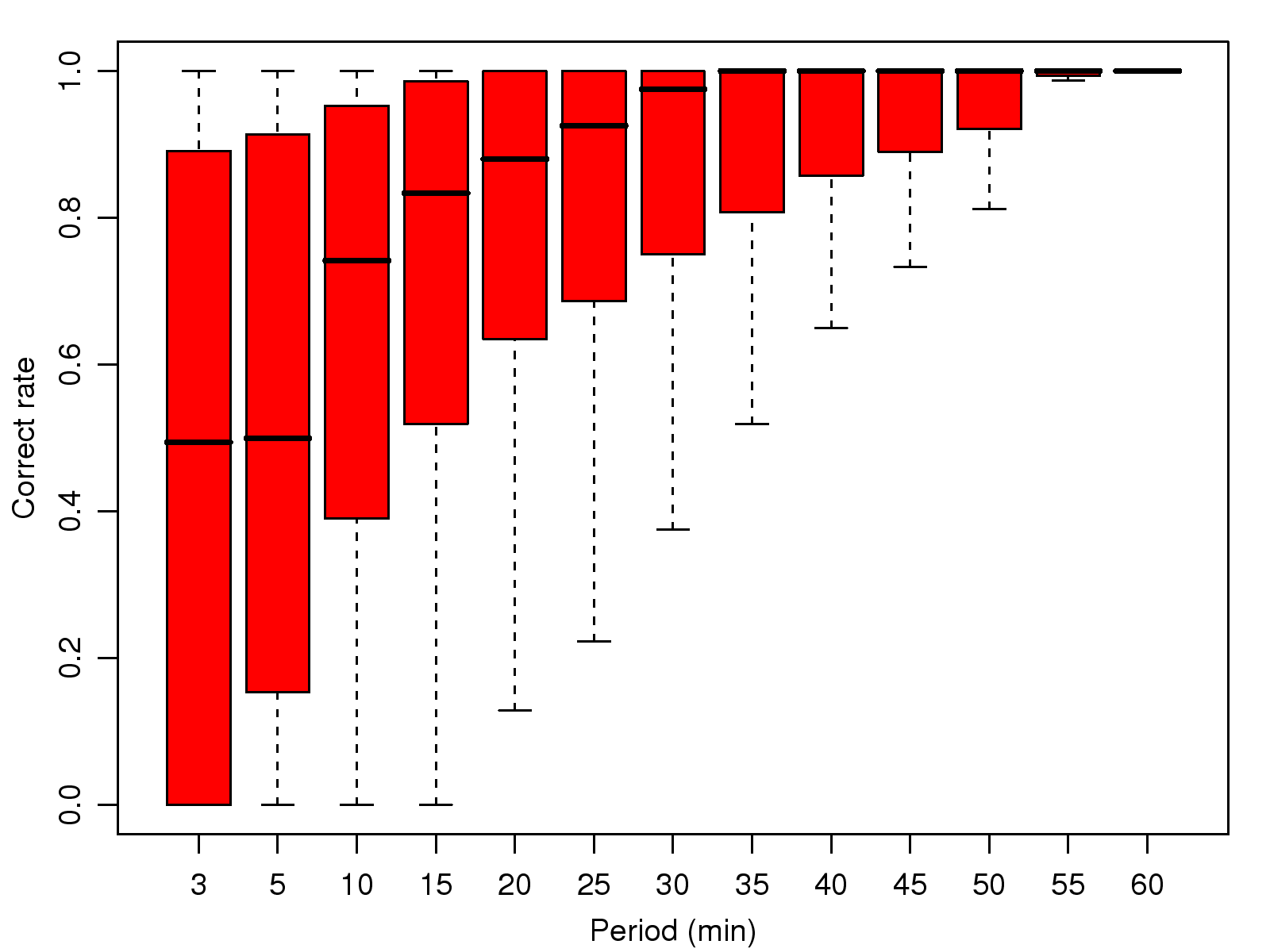
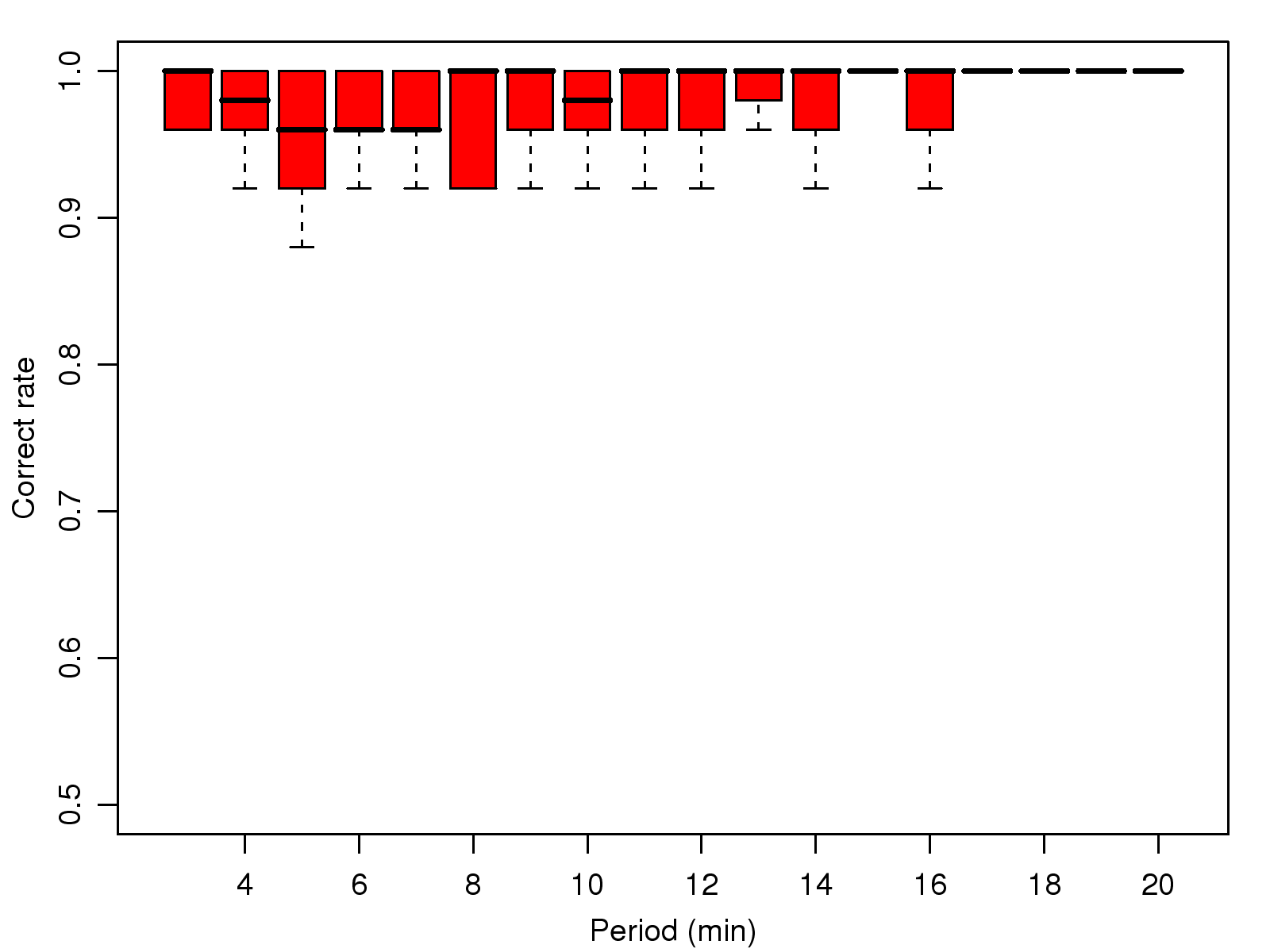
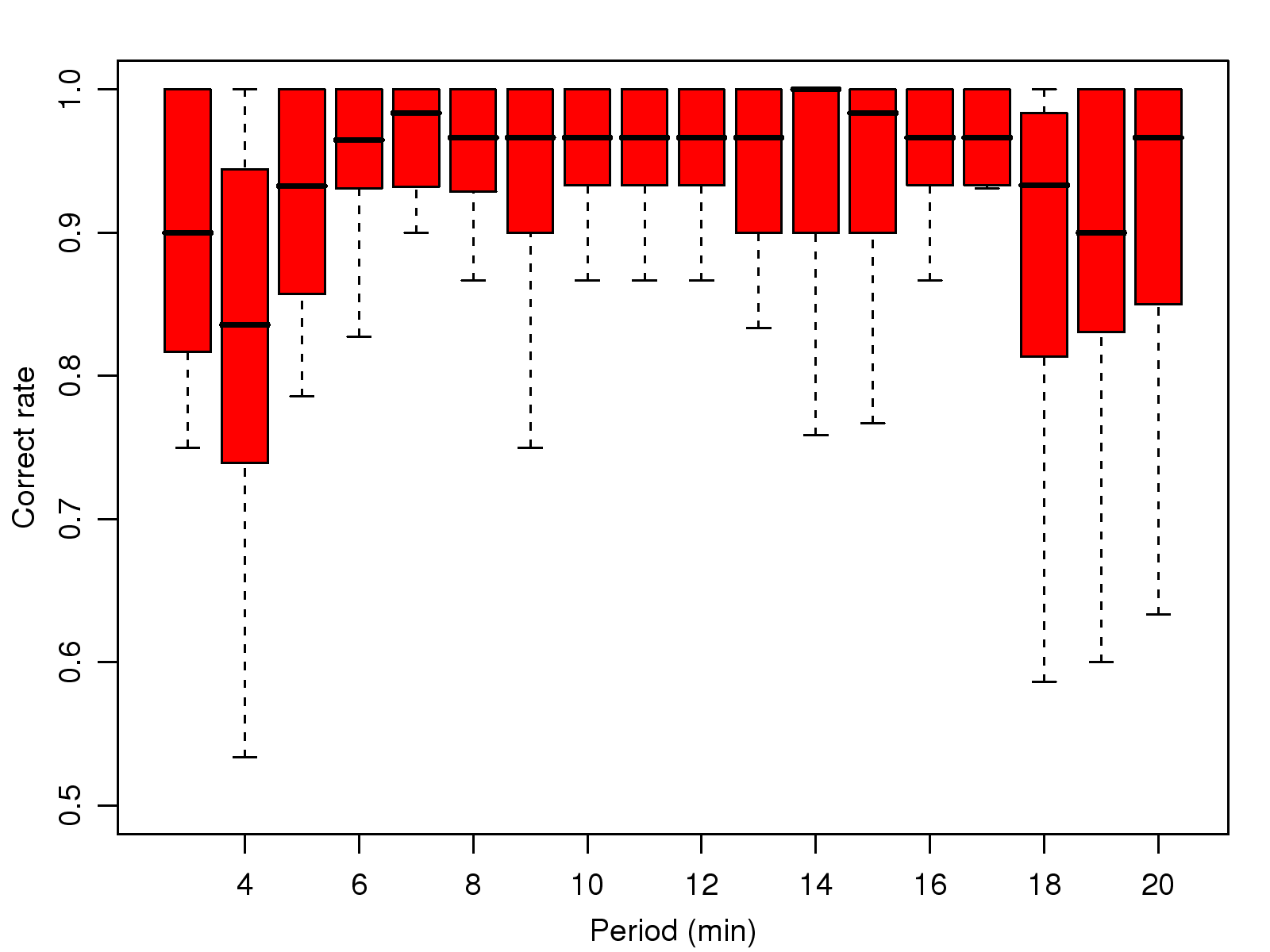
[1]
A. Broemme.
A classification of biometric signatures.
In
IEEE International Conference on Multimedia & Expo, 2003.
[2]
K.-T. Chen, P. Huang, and C.-L. Lei.
Game Traffic Analysis: An MMORPG Perspective.
Computer Networks, 50(16):3002-3023, 2006.
[3]
K.-T. Chen, J.-W. Jiang, P. Huang, H.-H. Chu, C.-L. Lei, and W.-C. Chen.
Identifying MMORPG Bots: A Traffic Analysis Approach.
In
Proceedings of ACM SIGCHI ACE'06, Los Angeles, USA, Jun
2006.
[4]
R. B. D'agostino and M. S. Stephen, editors.
Goodness-of-Fit Techniques.
Marcel Dekker, New York and Basel, 1986.
[5]
M. D. Griffiths, M. N. Davies, and D. Chappell.
Demographic factors and playing variables in online computer gaming.
CyberPsychology & Behavior, 7(4):479-487, Aug. 2004.
[6]
D. Guinier.
Identification by biometrics.
SIGSAC Rev., 8(2):1-11, 1990.
[7]
D. Gunetti and C. Picardi.
Keystroke analysis of free text.
ACM Trans. Inf. Syst. Secur., 8(3):312-347, 2005.
[8]
J.-Y. Ho, Y. Matsumoto, and R. Thawonmas.
MMOG player identification: A step toward CRM of MMOGs.
In
Proc. of the Sixth Pacific Rim International Workshop on
Multi-Agents, pages 81-92, Nov 2003.
[9]
A. Jain, A. Ross, and S. Prabhakar.
An introduction to biometric recognition.
IEEE Transactions on Circuits and Systems for Video Technology,
14(1):4-20, Jan 2004.
[10]
R. Joyce and G. Gupta.
Identity authentication based on keystroke latencies.
Commun. ACM, 33(2):168-176, 1990.
[11]
D. M. Kienzle and M. C. Elder.
Recent worms: a survey and trends.
In
WORM '03: Proceedings of the 2003 ACM workshop on Rapid
malcode, pages 1-10. ACM Press, 2003.
[12]
S. Kullback and R. A. Leibler.
On information and sufficiency.
In
Annals of Mathematical Statistics, volume 55, pages 79-86,
1951.
[13]
H. B. Mann and D. R. Whitney.
On a test of whether one of two random variables is stochastically
larger than the other.
Annals of Mathematical Statistics, 18:50-60, 1947.
[14]
F. J. Massey.
The Kolmogorov-Smirnov test for goodness of fit.
Journal of the American Statistical Association, 46:68-78,
1951.
[15]
A. Peacock, X. Ke, and M. Wilkerson.
Typing patterns: A key to user identification.
IEEE Security and Privacy, 2(5):40-47, 2004.
[16]
M. Pusara and C. E. Brodley.
User re-authentication via mouse movements.
In
VizSEC/DMSEC '04: Proceedings of the 2004 ACM workshop on
Visualization and data mining for computer security, pages 1-8. ACM Press,
2004.
[17]
R. Thawonmas, M. Kurashige, K. Iizuka, and M. Kantardzic.
Clustering online game users based on their trails using
self-organizing map.
In
Proceedings of ICEC 2006, pages 366-369, Sep 2006.
[18]
J. R. Vacca.
Identity Theft.
Prentice Hall PTR, 1 edition, Sep. 2002.
[19]
J. Yan and B. Randell.
A systematic classification of cheating in online games.
In
Proceedings of ACM SIGCOMM 2005 workshops on NetGames '05.
ACM Press, 2005.
[20]
S. Yeung, J. C. Lui, J. Liu, and J. Yan.
Detecting cheaters for multiplayer games: Theory, design and
implementation.
In
Proceedings of IEEE International Workshop on Networking
Issues in Multimedia Entertainment (NIME'06), Las Vegas, USA, Jan 2006.