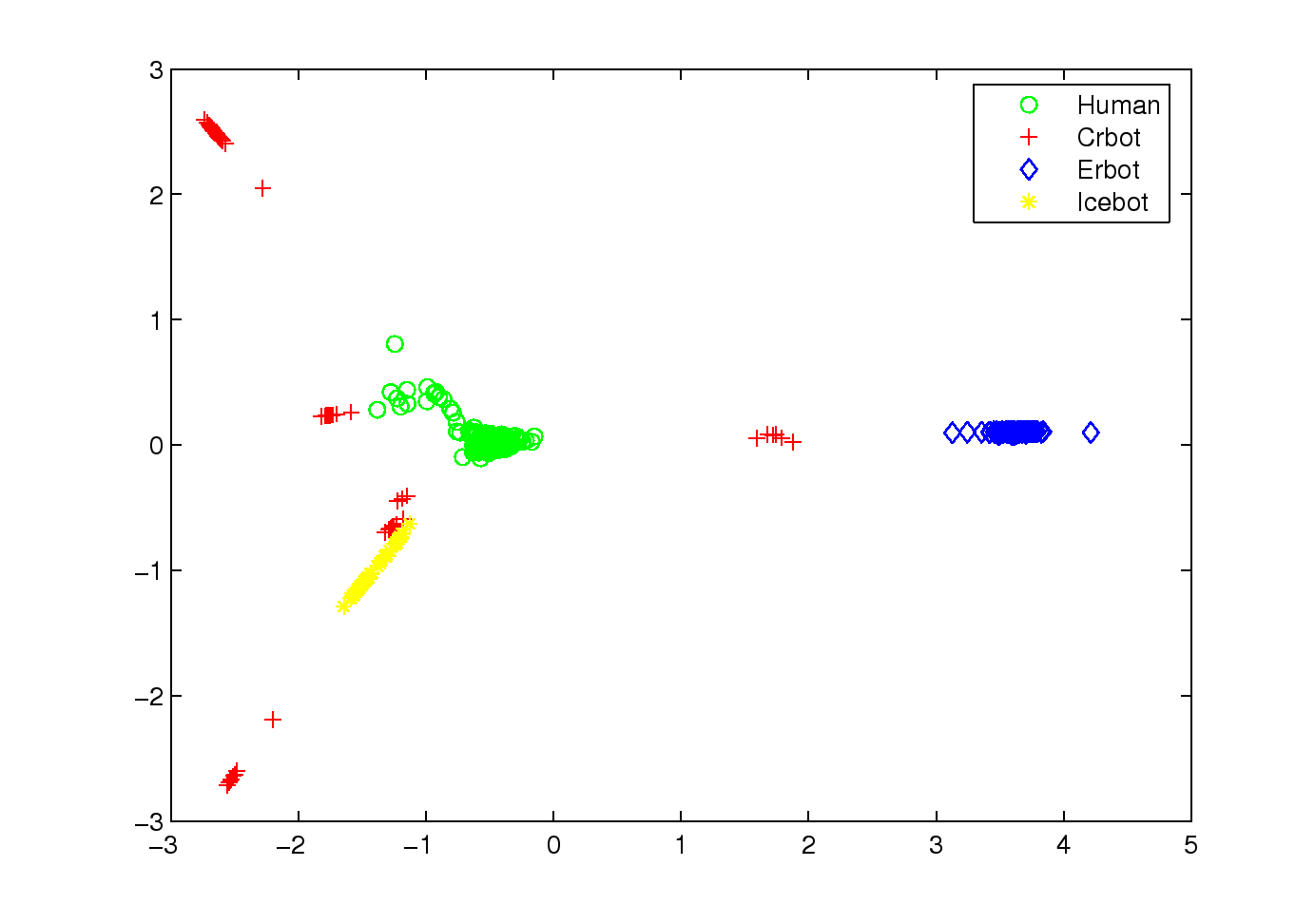
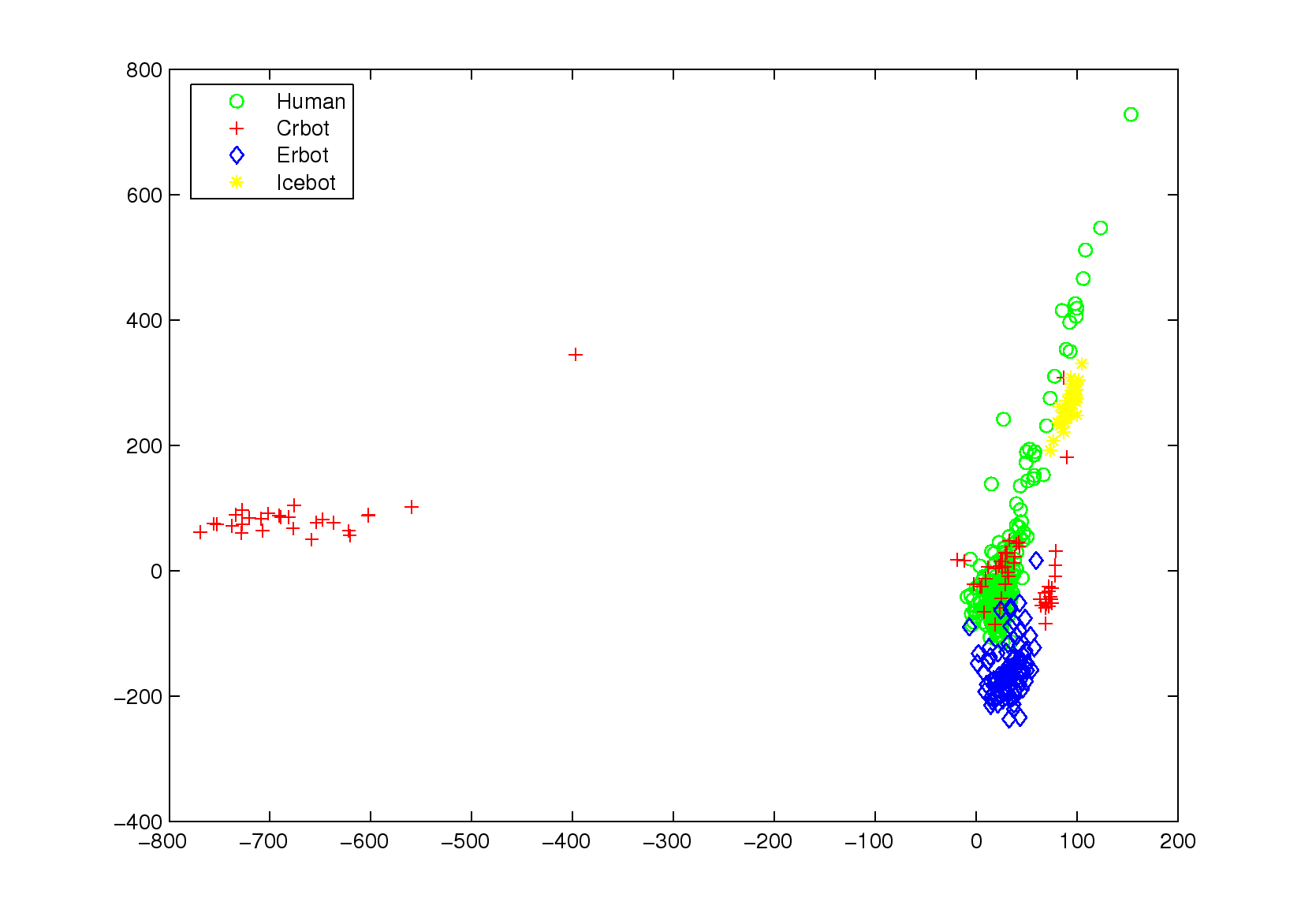
Table 2: The results of 10-fold cross-validation, which is repeated 10
times using six different classification methods. The results show the
average false positive rates, false negative rates and error rates.
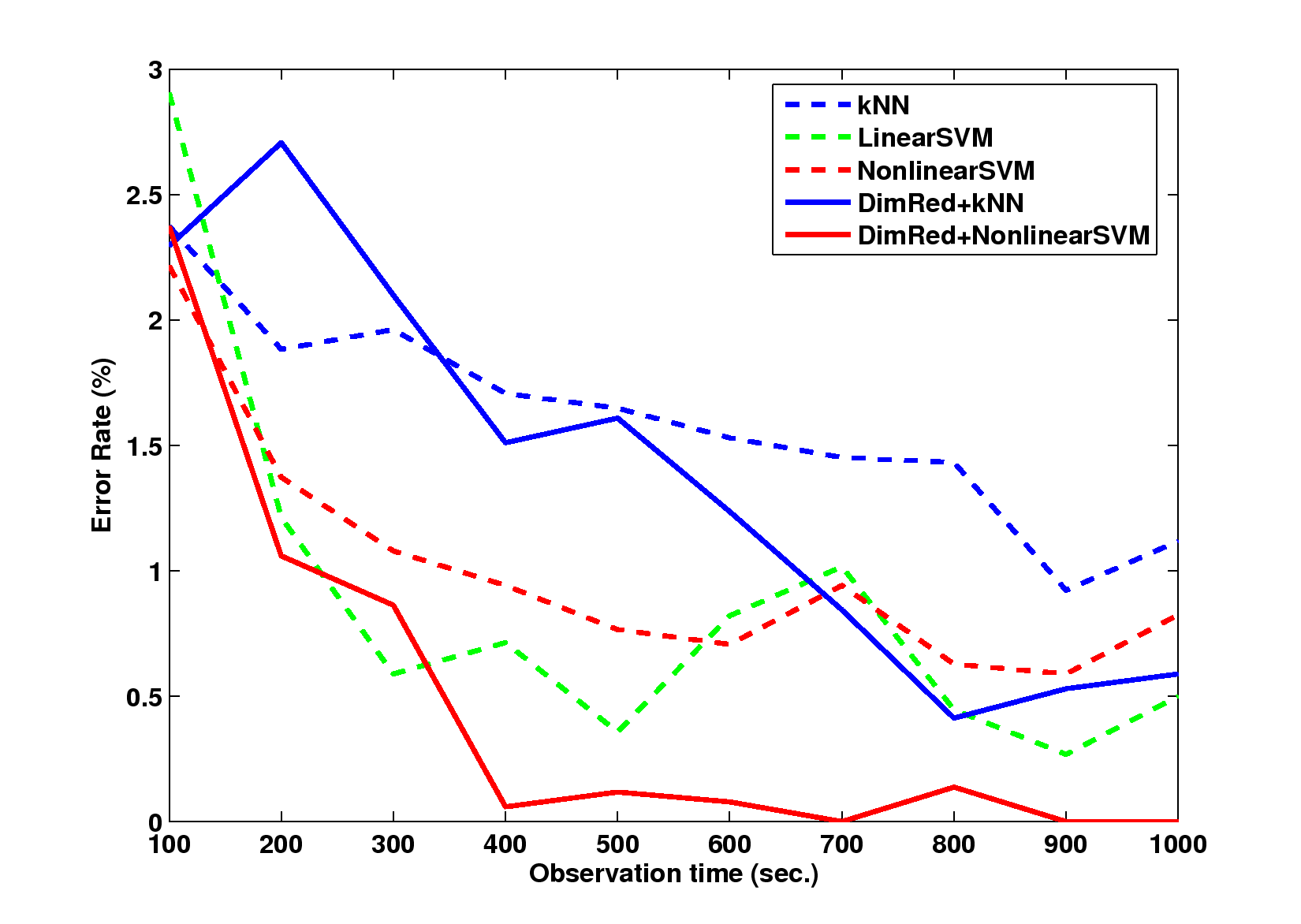
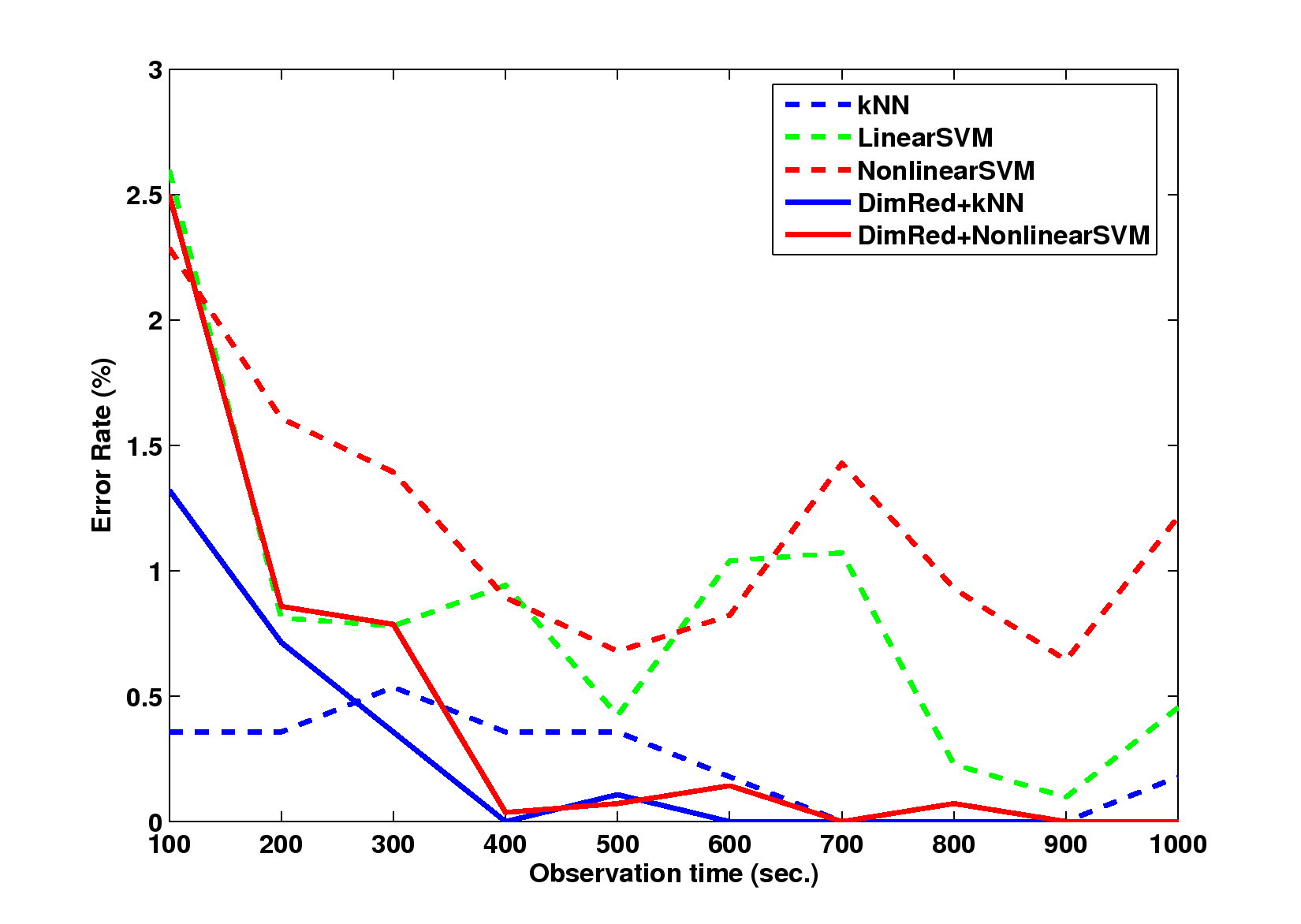
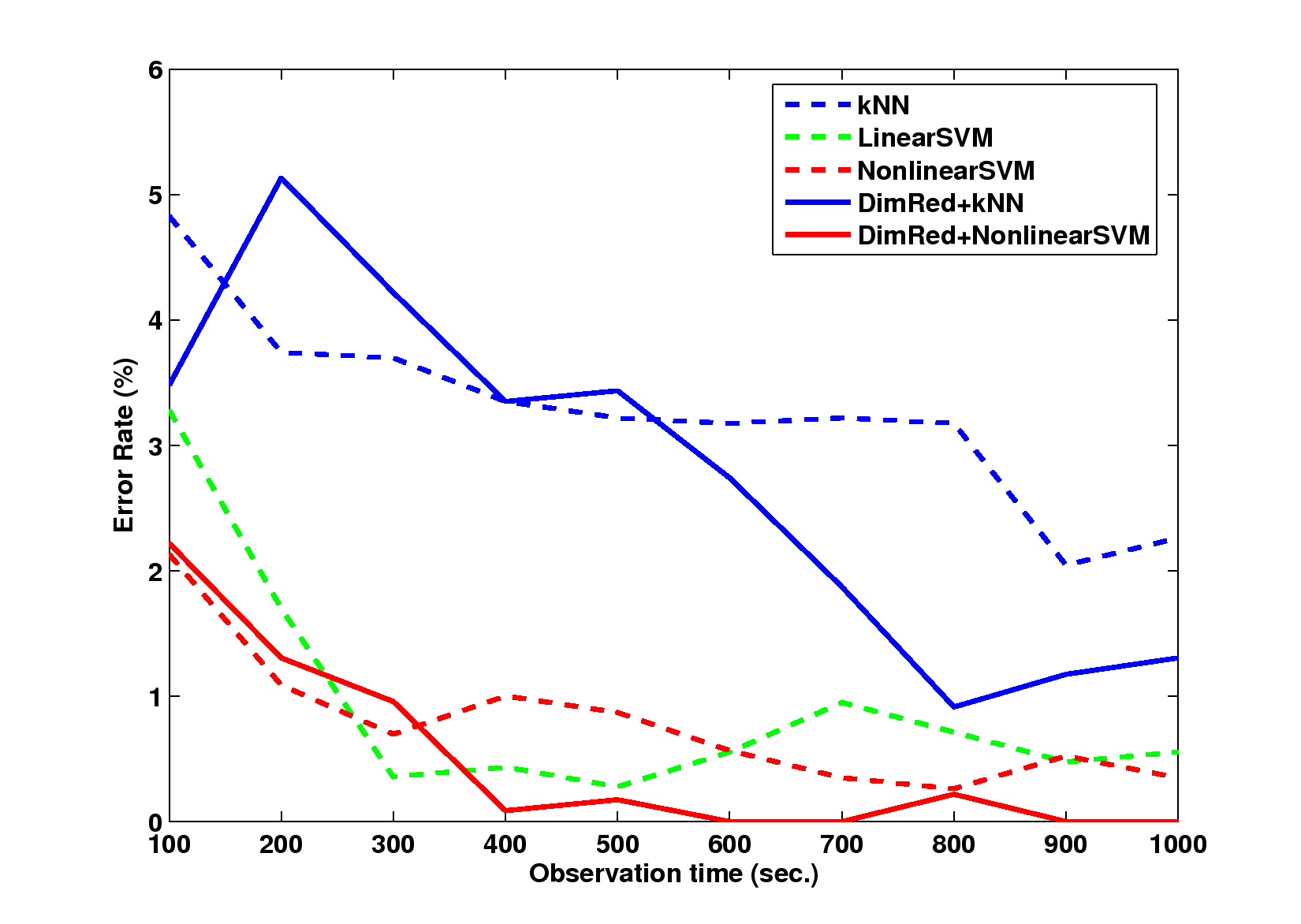
Figure 4: The error rates with different trajectory observation times,
measured in seconds: (a) error rate, (b) false positive rates, and (c)
false negative rates. The results are similar to those given in the
previous section: 1) the methods combined with Isomap outperforms those
without it; and 2) the methods based on SSVM outperform those based on
kNN, except those with false positive rates.
[1]
Id Software: id History.
http://www.idsoftware.com/business/history/.
[2]
id Software, Inc.
http://www.idsoftware.com/.
[3]
C. M. Bishop.
Pattern Recognition and Machine Learning.
Springer, 2006.
[4]
K.-T. Chen, J.-W. Jiang, P. Huang, H.-H. Chu, C.-L. Lei, and W.-C. Chen.
Identifying MMORPG Bots: A Traffic Analysis Approach.
In
Proceedings of ACM SIGCHI ACE'06, Los Angeles, USA, Jun
2006.
[5]
T. M. Cover and J. A. Thomas.
Elements of Information Theory (2nd Ed.).
Wiley-Interscience, July 2006.
[6]
T. F. Cox and M. A. A. Cox.
Multidimensional Scaling, Second Edition.
Chapman & Hall/CRC, 2000.
[7]
R. R. Feltrin.
Eraser Bot 1.01, May 2000.
http://downloads.gamezone.com/demos/d9862.htm.
[8]
P. Golle and N. Ducheneaut.
Preventing bots from playing online games.
Computers in Entertainment, 3(3):3-3, 2005.
[9]
H. Hotelling.
Analysis of a complex of statistical variables into principal
components.
J. of Educational Psychology, 24:417-441, 1933.
[10]
S. Ila, D. Mizerski, and D. Lam.
Comparing the effect of habit in the online game play of australian
and indonesian gamers.
In
Proceedings of the Australia and New Zealand Marketing
Association Conference, 2003.
[11]
C. J. C. Burges.
A tutorial on support vector machines for pattern recognition.
Data Mining and Knowledge Discovery, 2(2):121-167, 1998.
[12]
jibe.
ICE Bot 1.0, 1998.
http://ice.planetquake.gamespy.com/.
[13]
H. Kim, S. Hong, and J. Kim.
Detection of auto programs for MMORPGs.
In
Proceedings of AI 2005: Advances in Artificial Intelligence,
pages 1281-1284, 2005.
[14]
Y.-J. Lee and O. L. Mangasarian.
Ssvm: A smooth support vector machine for classification.
Comput. Optim. Appl., 20(1):5-22, 2001.
[15]
M. Malakhov.
CR Bot 1.15, May 2000.
http://arton.cunst.net/quake/crbot/.
[16]
T. P. Novak, D. L. Hoffman, and A. Duhachek.
The influence of goal-directed and experiential activities on online
flow experiences.
Journal of Consumer Psychology, 13(1):3-16, 2003.
[17]
S. T. Roweis and L. K. Saul.
Nonlinear dimensionality reduction by locally linear embedding.
Science, 290(5500):2323-2326, 2000.
[18]
B. Schölkopf and A. Smola.
Learning with Kernels Support Vector Machines, Regularization,
Optimization and Beyond.
MIT Press, Cambridge, MA, USA, 2002.
[19]
G. Shakhnarovich, T. Darrell, and P. Indyk.
Nearest-Neighbor Methods in Learning and Vision: Theory and
Practice.
The MIT Press, 2006.
[20]
J. B. Tenenbaum, V. de Silva, and J. C. Langford.
A global geometric framework for nonlinear dimensionality reduction.
Science, 290(5500):2319-2323, December 2000.
[21]
C. Thurau and C. Bauckhage.
Tactical waypoint maps: Towards imitating tactics in fps games.
In M. Merabti, N. Lee, and M. Overmars, editors,
Proc. 3rd
International Game Design and Technology Workshop and Conference (GDTW'05),
pages 140-144, 2005.
[22]
C. Thurau and C. Bauckhage.
Towards manifold learning for gamebot behavior modeling.
In
In Proc. Int. Conf. on Advances in Computer Entertainment
Technolog (ACE'05), pages 446-449, 2005.
[23]
C. Thurau, C. Bauckhage, and G. Sagerer.
Learning human-like movement behavior for computer games.
In
In Proc. 8th Int. Conf. on the Simulation of Adaptive
Behavior (SAB'04), pages 315-323. IEEE Press, 2004.
[24]
C. Thurau, C. Bauckhauge, and G. Sagerer.
Combining self organizing maps and multilayer perceptrons to learn
bot-behavior for a commercial game.
In
Proceedings of the GAME-ON03 Conference, pages 119-123,
2003.
[25]
C. Thurau, T. Paczian, and C. Bauckhage.
Is bayesian imitation learning the route to believable gamebots?
In
In Proc. GAME-ON North America, pages 3-9, 2005.
[26]
V. N. Vapnik.
The Nature of Statistical Learning Theory.
Springer, November 1999.
[27]
L. von Ahn, M. Blum, N. J. Hopper, and J. Langford.
CAPTCHA: Using hard AI problems for security.
In
Proceedings of Eurocrypt, pages 294-311, 2003.
[28]
S. Yeung, J. Lui, J. Liu, and J. Yan.
Detecting cheaters for multiplayer games: theory, design and
implementation.
Proc IEEE CCNC, 6:1178-1182.
[29]
S. F. Yeung, J. C. S. Lui, J. Liu, and J. Yan.
Detecting cheaters for multiplayer games: theory, design and
implementation.
Consumer Communications and Networking Conference, 2006. 3rd
IEEE, 2:1178-1182, 2006.