[1]
J. Constine, Facebook has users identify friends in photos to verify accounts,
prevent unauthorized access,
http://www.insidefacebook.com/2010/07/26/facebook-photos-verify/">http://www.insidefacebook.com/2010/07/26/facebook-photos-verify/,
online; accessed 2012 (2010).
[2]
J. Constine, Facebook asks every user for a verified phone number to prevent
security disaster,
http://techcrunch.com/2012/06/14/facebook-security-tips/">http://techcrunch.com/2012/06/14/facebook-security-tips/, online;
accessed 2012 (2012).
[3]
C. Technologies, Phone data makes 4.2 million* brits vulnerable to id theft,
http://www.credant.com/news-a-events/press-releases/69-phone-data-makes-42-million-brits-vulnerable-to-id-theft.html">http://www.credant.com/news-a-events/press-releases/69-phone-data-makes-42-million-brits-vulnerable-to-id-theft.html,
online; accessed 2012.
[4]
P. Mah, Stored passwords add to mobile security risks,
http://www.itbusinessedge.com/cm/blogs/mah/stored-passwords-add-to-mobile-security-risks/?cs=47183">http://www.itbusinessedge.com/cm/blogs/mah/stored-passwords-add-to-mobile-security-risks/?cs=47183,
online; accessed 2012 (2011).
[5]
R. Yu, Lost cellphones added up fast in 2011,
http://usatoday30.usatoday.com/tech/news/story/2012-03-22/lost-phones/53707448/1">http://usatoday30.usatoday.com/tech/news/story/2012-03-22/lost-phones/53707448/1,
online; accessed 2012 (2012).
[6]
E. Hansberry, Most consumers don't lock mobile phone via pin,
http://www.informationweek.com/mobility/security/most-consumers-dont-lock-mobile-phone-vi/231700155">http://www.informationweek.com/mobility/security/most-consumers-dont-lock-mobile-phone-vi/231700155,
online; accessed 2012 (2011).
[7]
Facebook, Removal of offline_access permission,
https://developers.facebook.com/roadmap/offline-access-removal/">https://developers.facebook.com/roadmap/offline-access-removal/,
online; accessed 2012.
[8]
M. Pusara, C. E. Brodley, User re-authentication via mouse movements, in: Proc.
of the ACM Workshop on Visualization and data mining for computer security,
2004, pp. 1-8.
[9]
S. Shepherd, Continuous authentication by analysis of keyboard typing
characteristics, in: European Convention on Security and Detection, 1995, pp.
111-114.
[10]
Y.-J. Lee, O. Mangasarian, SSVM: A smooth support vector machine for
classification, Computational Optimization and Applications 20 (1) (2001)
5-22.
[11]
S.-H. Wu, K.-P. Lin, C.-M. Chen, M.-S. Chen, Asymmetric support vector
machines: low false-positive learning under the user tolerance, in: Proc. of
the 14th ACM KDD 2008, 2008, pp. 749-757.
[12]
J. He, W. Chu, Z. Liu, Inferring privacy information from social networks,
Intelligence and Security Informatics (2006) 154-165.
[13]
E. Zheleva, L. Getoor, To join or not to join: the illusion of privacy in
social networks with mixed public and private user profiles, in: Proc. of the
18th Int'l Conf. on World Wide Web (WWW), 2009, pp. 531-540.
[14]
C. Tang, K. Ross, N. Saxena, R. Chen, What's in a name: A study of names,
gender inference, and gender behavior in facebook, Database Systems for
Adanced Applications (2011) 344-356.
[15]
L. Bilge, T. Strufe, D. Balzarotti, E. Kirda, All your contacts are belong to
us: automated identity theft attacks on social networks, in: Proceedings of
the 18th international conference on World wide web, ACM, 2009, pp. 551-560.
[16]
L. Jin, H. Takabi, J. B. Joshi,
http://doi.acm.org/10.1145/1943513.1943520">Towards active detection of
identity clone attacks on online social networks, in: Proceedings of the
First ACM Conference on Data and Application Security and Privacy, CODASPY
'11, ACM, 2011, pp. 27-38.
http://dx.doi.org/10.1145/1943513.1943520">doi:10.1145/1943513.1943520.
URL
http://doi.acm.org/10.1145/1943513.1943520">http://doi.acm.org/10.1145/1943513.1943520
[17]
A. Felt, D. Evans, Privacy protection for social networking APIs, Web 2.0
Security and Privacy (W2SP).
[18]
R. Wishart, D. Corapi, A. Madhavapeddy, M. Sloman, Privacy butler: A personal
privacy rights manager for online presence, in: Proc. of the 8th IEEE PERCOM
Workshops, 2010, pp. 672-677.
[19]
S. Mahmood, Y. Desmedt, Your facebook deactivated friend or a cloaked spy, in:
IEEE International Workshop on Security and Social Networking (SESOC 2012),
2012, pp. 367-373.
[20]
Facebook, Facebook security,
http://www.facebook.com/security">http://www.facebook.com/security, online;
accessed 2012.
[21]
Facebook, Facebook's privacy policy - 2. information we receive,
http://www.facebook.com/note.php">http://www.facebook.com/note.php, online; accessed 2012 (2009).
[22]
T. F. Lunt, R. Jagannathan, R. Lee, S. Listgarten, D. L. Edwards, P. G.
Neumann, H. S. Javitz, A. Valdes, IDES: The enhanced prototype-a real-time
intrusion-detection expert system, in: SRI International, 1988.
[23]
G. K. Kuchimanchi, V. V. Phoha, K. S. Balagani, S. R. Gaddam, Dimension
reduction using feature extraction methods for real-time misuse detection
systems, in: IEEE Information Assurance Workshop 2004, IEEE, 2004, pp.
195-202.
[24]
D.-K. Kang, D. Fuller, V. Honavar, Learning classifiers for misuse detection
using a bag of system calls representation, in: Intelligence and Security
Informatics, Springer, 2005, pp. 511-516.
[25]
S. Mukkamala, A. H. Sung, A. Abraham, Intrusion detection using an ensemble of
intelligent paradigms, Journal of network and computer applications 28 (2)
(2005) 167-182.
[26]
R. Cathey, L. Ma, N. Goharian, D. Grossman, Misuse detection for information
retrieval systems, in: Proceedings of CIKM 2003, ACM, 2003, pp. 183-190.
[27]
C. Y. Chung, M. Gertz, K. Levitt, DEMIDS: A misuse detection system for
database systems, in: Integrity and Internal Control in Information Systems,
Springer, 2000, pp. 159-178.
[28]
M. Meier, A model for the semantics of attack signatures in misuse detection
systems, in: Information Security, Springer, 2004, pp. 158-169.
[29]
P. Helman, G. Liepins, Statistical foundations of audit trail analysis for the
detection of computer misuse, IEEE Transactions on Software Engineering
19 (9) (1993) 886-901.
[30]
S. J. Stolfo, S. Hershkop, K. Wang, O. Nimeskern, C.-W. Hu, Behavior profiling
of email, in: Intelligence and Security Informatics, Springer, 2003, pp.
74-90.
[31]
T. Feng, Z. Liu, K.-A. Kwon, W. Shi, B. Carbunar, Y. Jiang, N. Nguyen,
Continuous mobile authentication using touchscreen gestures, in: Proc. of
IEEE Conf. on Technologies for Homeland Security, 2012, pp. 451-456.
[32]
K. Niinuma, A. K. Jain, Continuous user authentication using temporal
information, in: Proc. of Biometric Technology for Human Identification VII,
2010, p. 76670L.
[33]
K. Niinuma, U. Park, A. K. Jain, Soft biometric traits for continuous user
authentication, IEEE Trans. on Information Forensics and Security 5 (4)
(2010) 771-780.
[34]
R. H. Yap, T. Sim, G. X. Kwang, R. Ramnath, Physical access protection using
continuous authentication, in: Proc. of IEEE Conf. on Technologies for
Homeland Security, 2008, pp. 510-512.
[35]
M. Egele, G. Stringhini, C. Kruegel, G. Vigna, Compa: Detecting compromised
accounts on social networks, in: Symposium on Network and Distributed System
Security (NDSS), 2013.
[36]
K. Hampton, Social networking sites and our lives part 2: Who are social
networking site users?,
http://pewinternet.org/Reports/2011/Technology-and-social-networks/Part-2/Facebook-activities.aspx">http://pewinternet.org/Reports/2011/Technology-and-social-networks/Part-2/Facebook-activities.aspx,
online; accessed 2012 (2011).
[37]
A. N. Joinson, Looking at, looking up or keeping up with people?: motives and
use of Facebook, in: Proc. of ACM CHI 2008, 2008, pp. 1027-1036.
[38]
P. Domingos, A few useful things to know about machine learning, Communication
of the ACM 55 (10).
[39]
C.-M. Huang, Y.-J. Lee, D. Lin, S.-Y. Huang, Model selection for support vector
machines via uniform design, Computational Statistics & Data Analysis 52 (1)
(2007) 335-346.
[40]
I. Witten, E. Frank, M. Hall, Data Mining: Practical Machine Learning Tools and
Techniques, Morgan Kaufmann, 2005.
[41]
J. Zhu, S. Rosset, T. Hastie, R. Tibshirani, 1-norm support vector machines,
in: Advances in Neural Information Processing Systems, Vol. 16, 2003, pp.
49-56.
[42]
R. Tibshirani, Regression shrinkage and selection via the lasso, Journal of the
Royal Statistical Society. Series B (Methodological) (1996) 267-288.
[43]
M. Figueiredo, R. Nowak, S. Wright, Gradient projection for sparse
reconstruction: Application to compressed sensing and other inverse problems,
IEEE Journal of Selected Topics in Signal Processing 1 (4) (2007) 586-597.
[44]
M. J. Zaki, Sequence mining in categorical domains: incorporating constraints,
in: Proceedings of the 9th CIKM, ACM, 2000, pp. 422-429.
[45]
K.-T. Chen, J.-Y. Chen, C.-R. Huang, C.-S. Chen, Fighting phishing with
discriminative keypoint features, IEEE Internet Computing (2009) 30-37.
[]
Shan-Hung Wu is currently an associate professor in the Department of
Computer Science, National Tsing Hua University, Hsinchu, Taiwan. He
received the Ph.D. degree from the Department of Electrical Engineering,
respectively, National Taiwan University, Taipei, Taiwan. Before joining
the National Tsing Hua University, he was a senior research scientist at
Telcordia Technologies Inc.. He has published many research papers in
top-tier conferences, such as ICML, KDD, INFOCOM, Mobihoc, ICDE, and
ICDCS. Dr. Wu's research interests include machine learning, data
mining, database systems, and mobile applications.
[]
Man-Ju Chou received the B.S degree and M.S. degree in computer
science from the National Taiwan University of Science and Technology in
2011 and 2013. Since then, she has been a data engineer at Yahoo APAC
Data Team, working on business intelligence and CRM
system.
[]
Chun-Hsiung Tseng received his B.S. in computer science from National
National ChengChi University, and received both M.S. and Ph.D. in
computer science from National Taiwan University. He was a research
assistant of Institute of Information Science, Academia Sinica in
2003-2010. He was a faculty member of Department of Computer Information
and Network Engineering, Lunghwa University of Science and Technology in
2010-2013. His current position is a faculty member of Department of
Information Management, Nanhua University. His research interests
include big data analysis, crowd intelligence, e-learning systems, and
Web information extraction.
[]
Yuh-Jye Lee received the PhD degree in Computer Science from the
University of Wisconsin-Madison in 2001. He is currently a Professor of
Department of Computer Science and Information Engineering at National
Taiwan University of Science and Technology. He also serves as a
principal investigator at the Intel-NTU Connected Context Computing
Center. His research is primarily rooted in optimization theory and
spans a range of areas including network and information security,
machine learning, big data, data mining, numerical optimization and
operations research. During the last decade, Dr. Lee has developed many
learning algorithms in supervised learning, semi-supervised learning and
unsupervised learning as well as linear/nonlinear dimension reduction.
His recent major research is applying machine learning to information
security problems such as network intrusion detection, anomaly
detection, malicious URLs detection and legitimate user identification.
Currently, he focus on online learning algorithms for dealing with large
scale datasets, stream data mining and behavior based anomaly detection
for the needs of big data, Internet of Things data analytics and machine
to machine communication security problems.
[]
Kuan-Ta Chen (a.k.a. Sheng-Wei Chen) (S'04-M'06-SM'15) is a Research
Fellow at the Institute of Information Science and the Research Center
for Information Technology Innovation (joint appointment) of Academia
Sinica. Dr. Chen received his Ph.D. in Electrical Engineering from
National Taiwan University in 2006, and received his B.S. and M.S. in
Computer Science from National Tsing-Hua University in 1998 and 2000,
respectively. His research interests include quality of experience,
multimedia systems, and social computing. He has been an Associate
Editor of
ACM Transactions on Multimedia Computing,
Communications, and Applications (TOMM) since 2015. He is a Senior
Member of ACM and a Senior Member of IEEE.
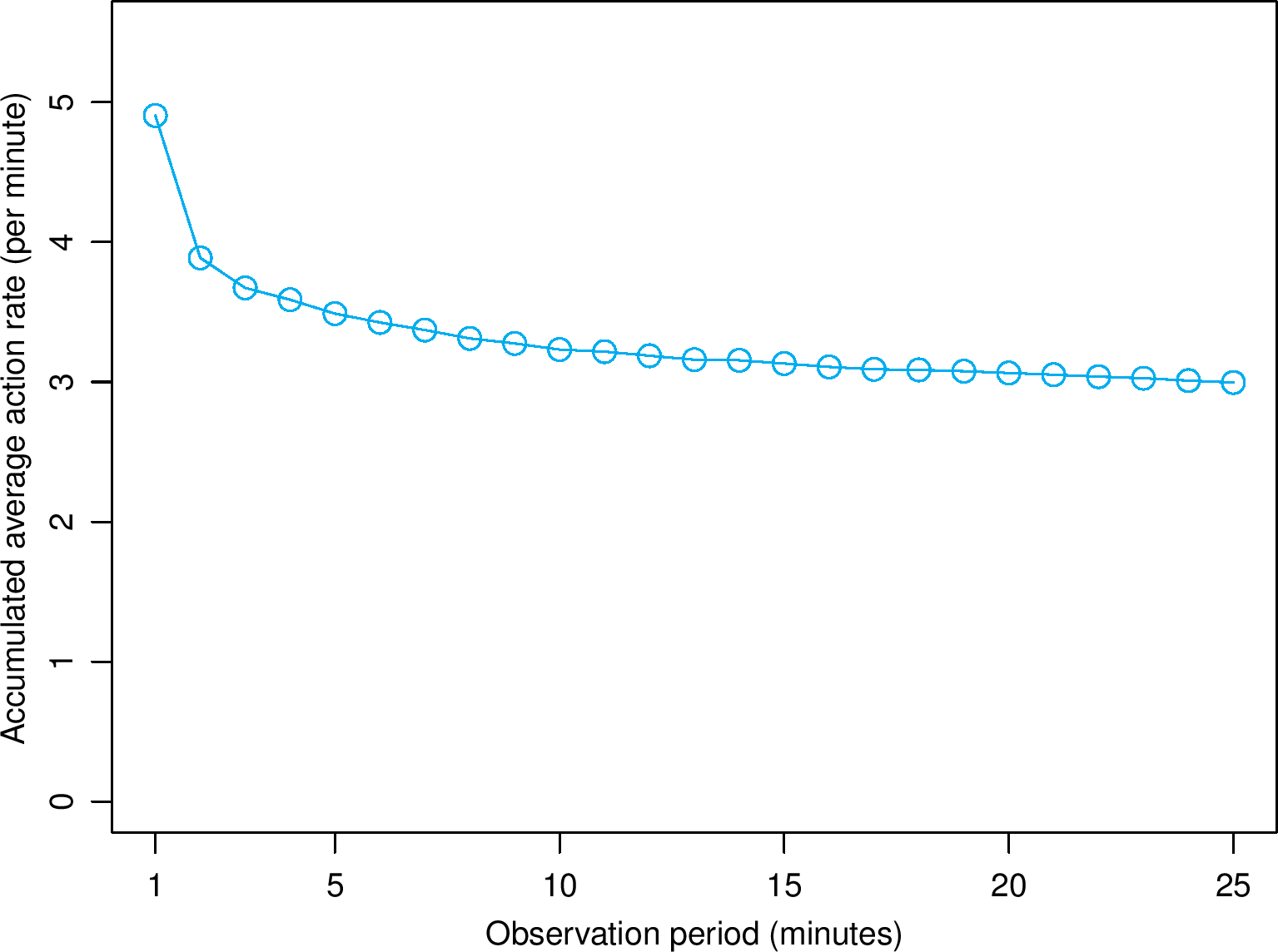 (a) Action rate of stalkers
(a) Action rate of stalkers
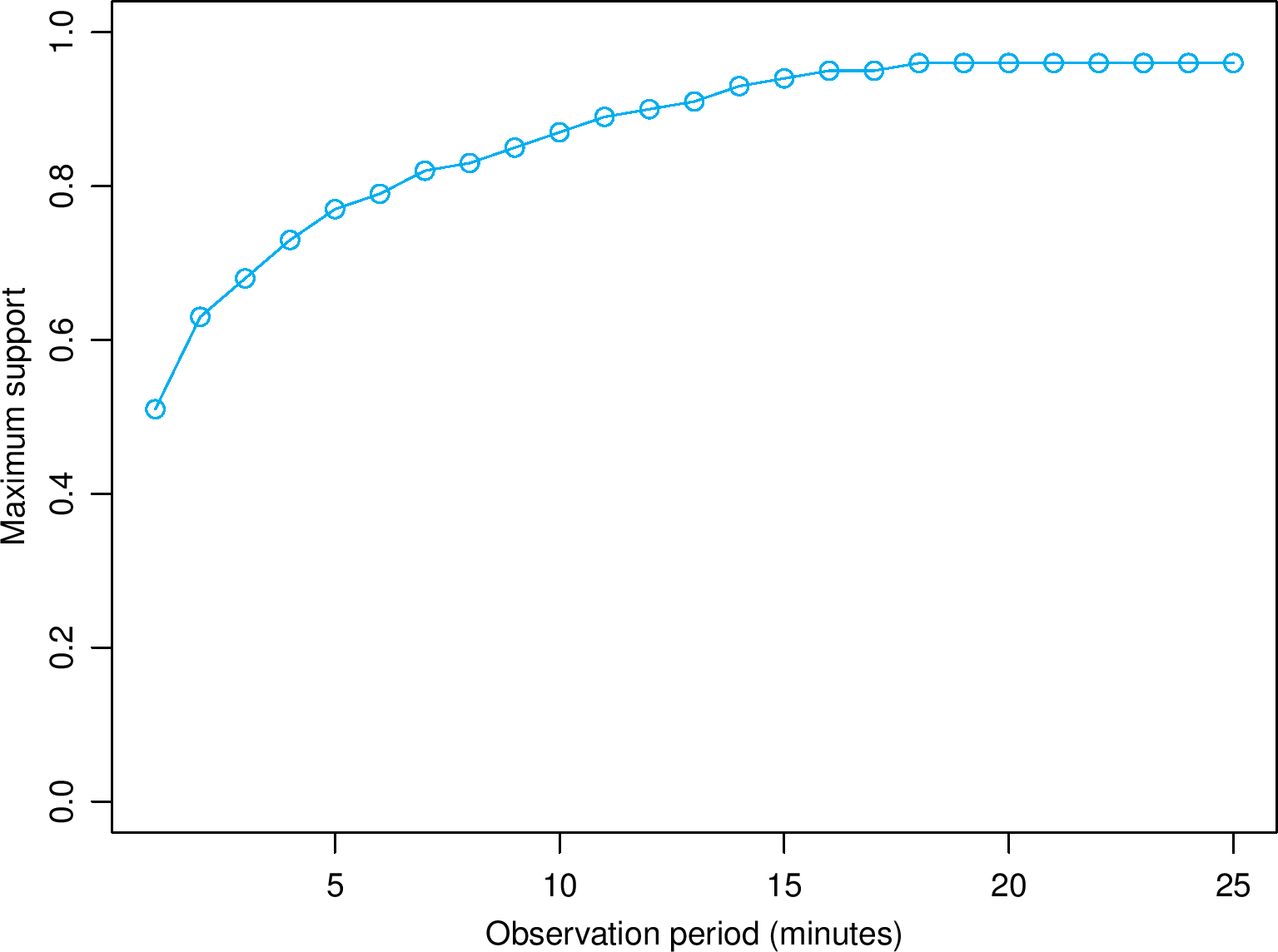 (b) Maximum support of frequent action patterns
of stalkers
(b) Maximum support of frequent action patterns
of stalkers
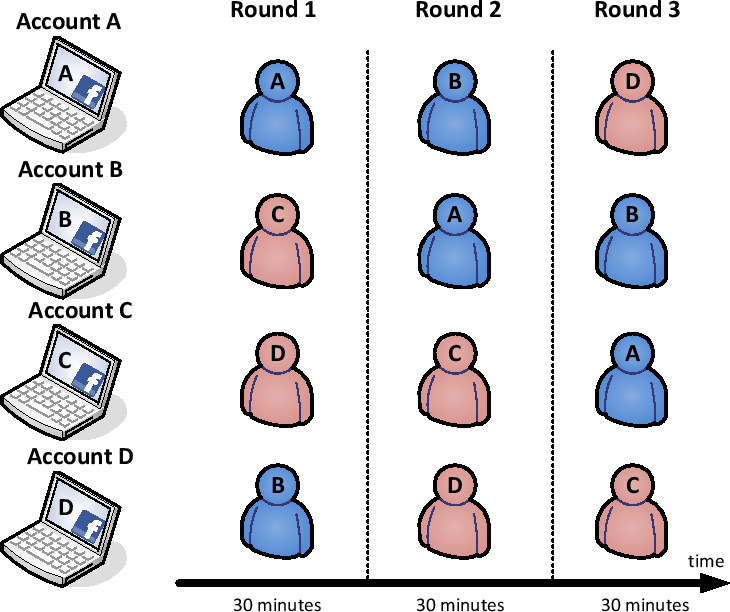
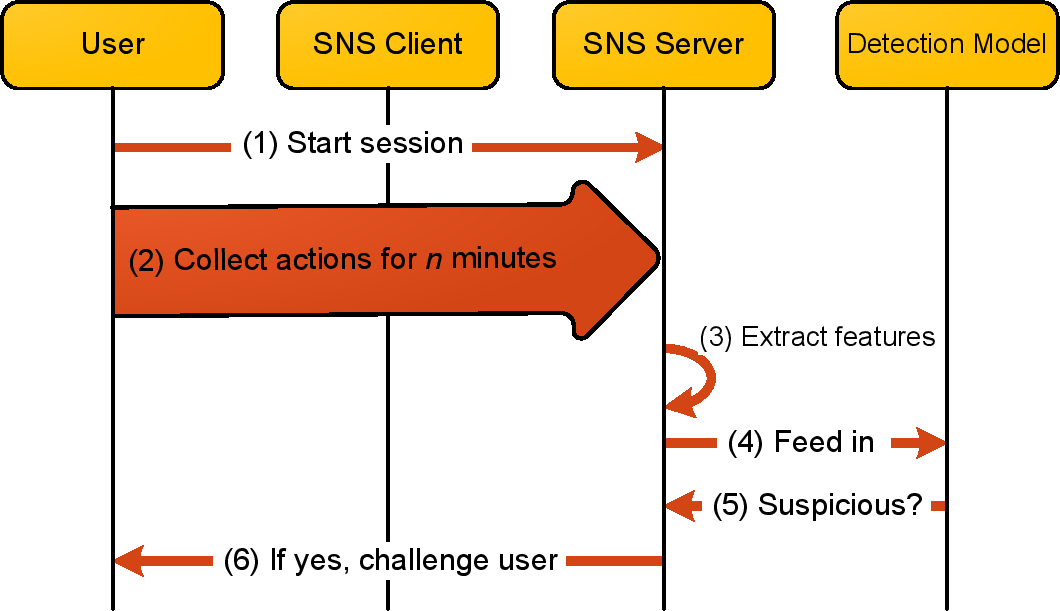 For the server, the runtime cost of the scheme is low because it exploits the role-driven
behavioral diversity property. As a result, only one detection model is needed for
all SNS users. Note that, although we utilize a two-class detection model to distinguish
stalkers from account owners, the scheme can be easily extended to identify account
owners, acquaintances, and strangers in a multi-class detection model.
We train the detection model with the labeled sessions collected earlier. Clearly, the
effectiveness of the detection scheme depends to a large extent on the quality of the
predictions made by the detection model. Thus, to obtain high-quality predictions, we
take the following rigorous steps to train the model.
For the server, the runtime cost of the scheme is low because it exploits the role-driven
behavioral diversity property. As a result, only one detection model is needed for
all SNS users. Note that, although we utilize a two-class detection model to distinguish
stalkers from account owners, the scheme can be easily extended to identify account
owners, acquaintances, and strangers in a multi-class detection model.
We train the detection model with the labeled sessions collected earlier. Clearly, the
effectiveness of the detection scheme depends to a large extent on the quality of the
predictions made by the detection model. Thus, to obtain high-quality predictions, we
take the following rigorous steps to train the model.
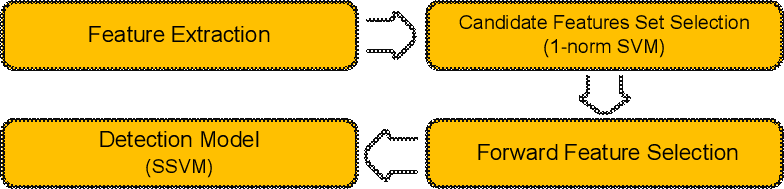 The feature selection process is divided into two stages, as shown in
Figure 4. In the first stage, we use the 1-norm SVM [41] to
obtain a set of candidate features. Then, in the second stage, we use the forward
feature selection [40] algorithm to select the best features from the candidate
set for training the detection model.
Unlike 2-norm SVM, which minimizes ||w||22 in its
objective,
1-norm SVM minimizes ||w||12 (called the LASSO penalty [42]). We utilize 1-norm SVM to derive the
candidate set because it usually finds a sparse w (i.e., a w that
tends to contain zeros) thanks to its "compressed sensing" interpretation [43]. To
compile the candidate set, we only keep features that correspond to the non-zeros in
w, as the features that correspond to zeros are usually redundant or
noisy [41]. Next, we use the forward feature selection algorithm to select the
final features from the candidate set. Initially, the set for storing the final features
is empty. In each step, the algorithm selects one feature from the candidate set that
yields the best improvement in SSVM's prediction accuracy5 of SSVM and adds it to the feature
set. The above step is repeated until the candidate set is empty, or there are no
features in the candidate set can further improve the prediction accuracy.
The feature selection process is divided into two stages, as shown in
Figure 4. In the first stage, we use the 1-norm SVM [41] to
obtain a set of candidate features. Then, in the second stage, we use the forward
feature selection [40] algorithm to select the best features from the candidate
set for training the detection model.
Unlike 2-norm SVM, which minimizes ||w||22 in its
objective,
1-norm SVM minimizes ||w||12 (called the LASSO penalty [42]). We utilize 1-norm SVM to derive the
candidate set because it usually finds a sparse w (i.e., a w that
tends to contain zeros) thanks to its "compressed sensing" interpretation [43]. To
compile the candidate set, we only keep features that correspond to the non-zeros in
w, as the features that correspond to zeros are usually redundant or
noisy [41]. Next, we use the forward feature selection algorithm to select the
final features from the candidate set. Initially, the set for storing the final features
is empty. In each step, the algorithm selects one feature from the candidate set that
yields the best improvement in SSVM's prediction accuracy5 of SSVM and adds it to the feature
set. The above step is repeated until the candidate set is empty, or there are no
features in the candidate set can further improve the prediction accuracy.
 We observe that the ratio of positive instances to negative instances in the dataset D
is 1.78:1. The imbalance tends to yield a higher FPR. To resolve this issue, we use an
oversampling approach to randomly select and then duplicate 78 negative instances
to balance the ratio between positive and negative instances. The effect of duplicating
an instance is to double the penalty if we misclassify the instance. Therefore, by
duplicating the negative instances in D we can avoid aliasing and reduce the FPR. Note
that because the oversampling technique causes randomness, we train 10 models and average
their results. Table IV shows the results achieved by our model
with and without oversampling. We can see that the oversampling can control
the trade-off between FPR and FNR.
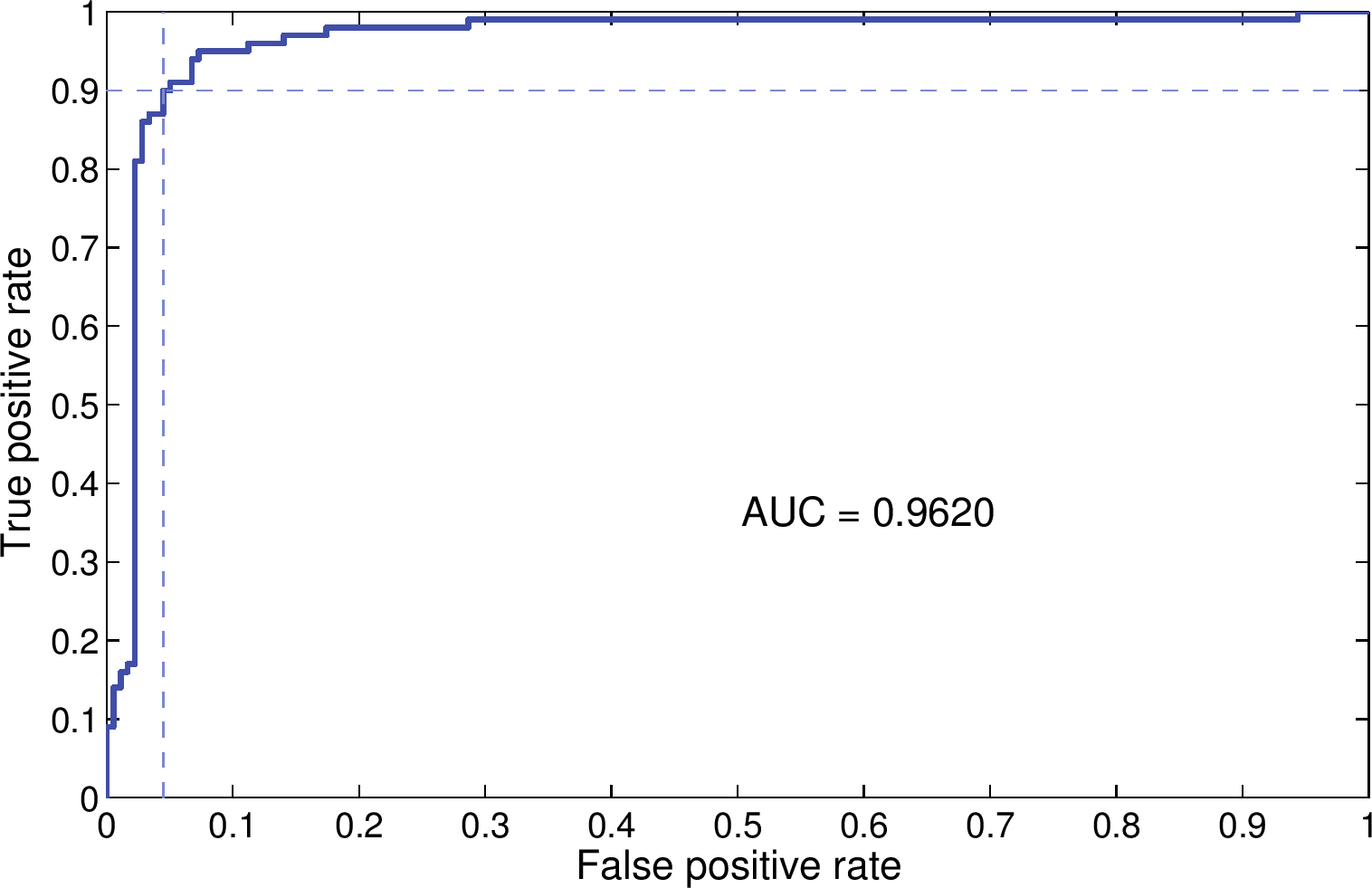
Figure 6 shows the ROC curve and AUC of our model when feature selection
and oversampling are applied. The AUC is fairly high (0.962); while the ROC curve shows
that the model can achieve a TPR of 90% TPR and a FPR of 4.5%.
We observe that the ratio of positive instances to negative instances in the dataset D
is 1.78:1. The imbalance tends to yield a higher FPR. To resolve this issue, we use an
oversampling approach to randomly select and then duplicate 78 negative instances
to balance the ratio between positive and negative instances. The effect of duplicating
an instance is to double the penalty if we misclassify the instance. Therefore, by
duplicating the negative instances in D we can avoid aliasing and reduce the FPR. Note
that because the oversampling technique causes randomness, we train 10 models and average
their results. Table IV shows the results achieved by our model
with and without oversampling. We can see that the oversampling can control
the trade-off between FPR and FNR.
Figure 6 shows the ROC curve and AUC of our model when feature selection
and oversampling are applied. The AUC is fairly high (0.962); while the ROC curve shows
that the model can achieve a TPR of 90% TPR and a FPR of 4.5%.
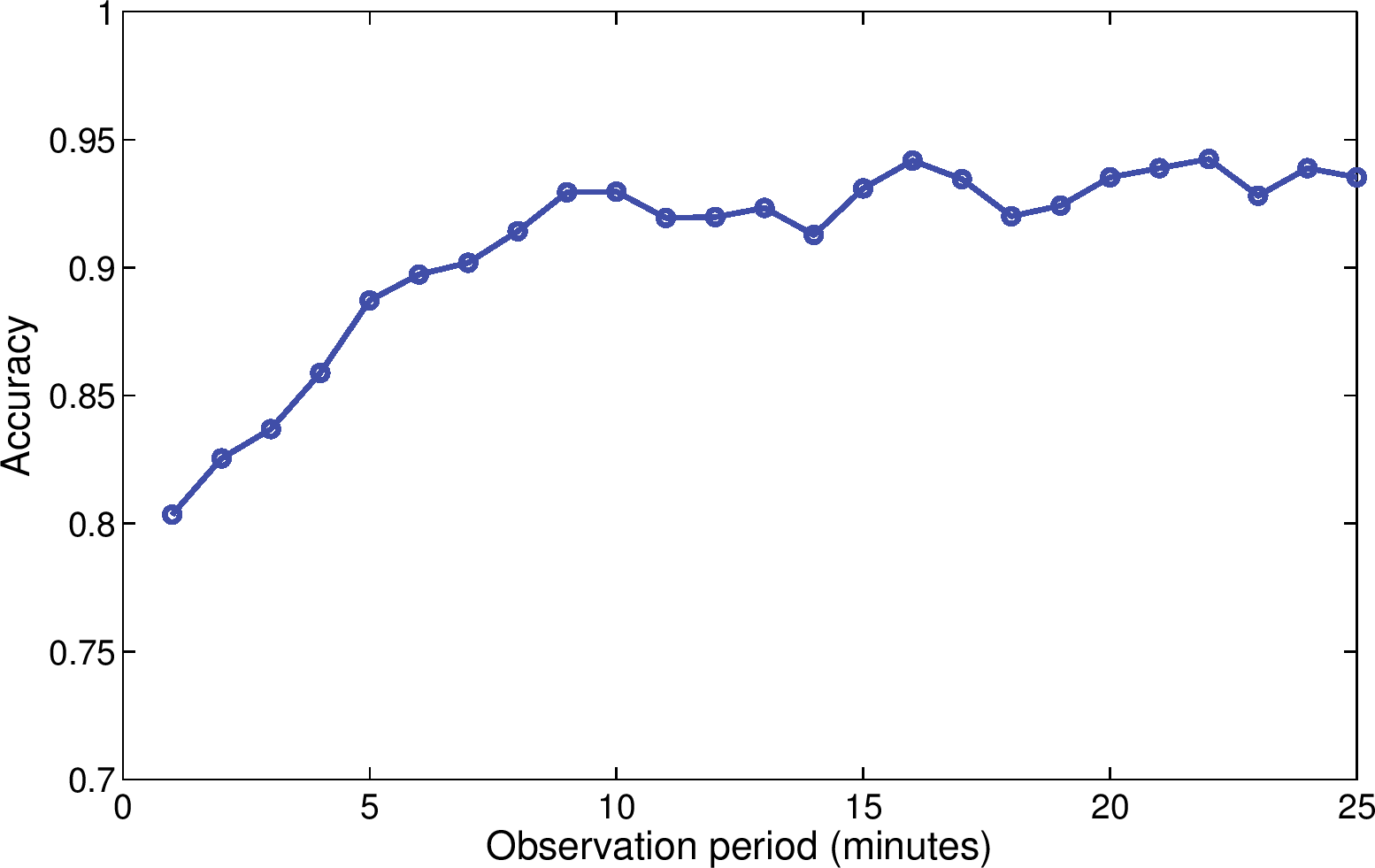
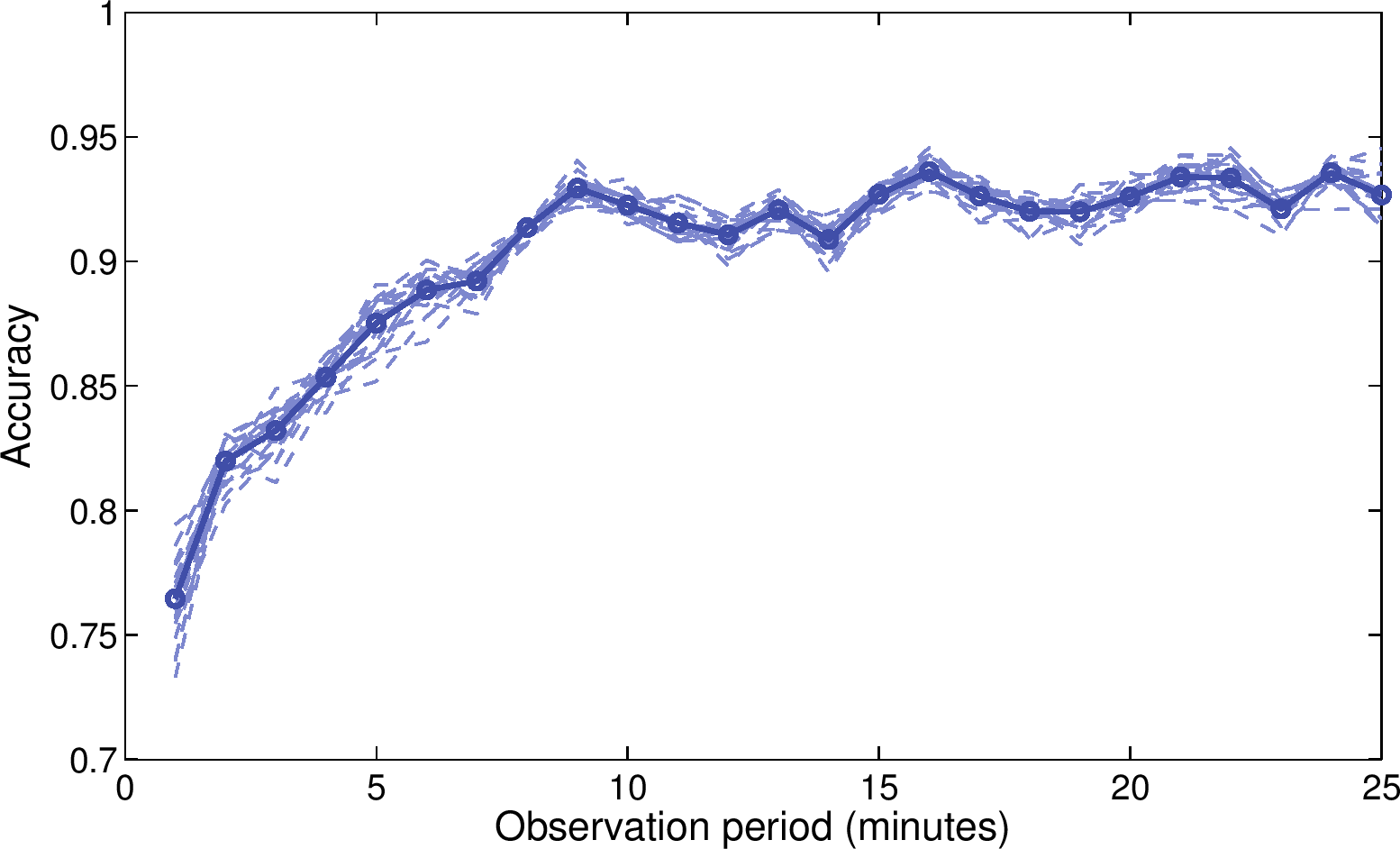
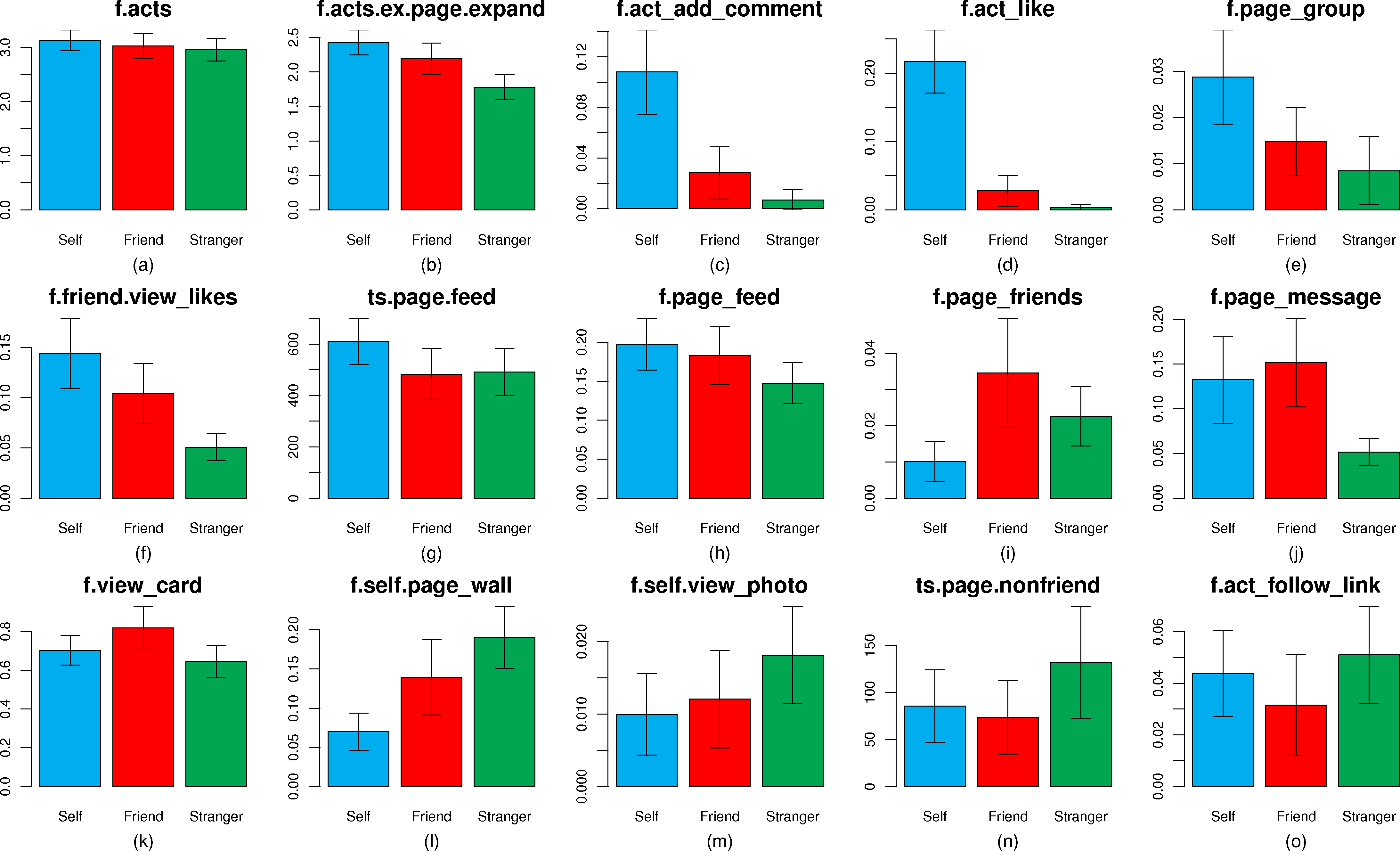
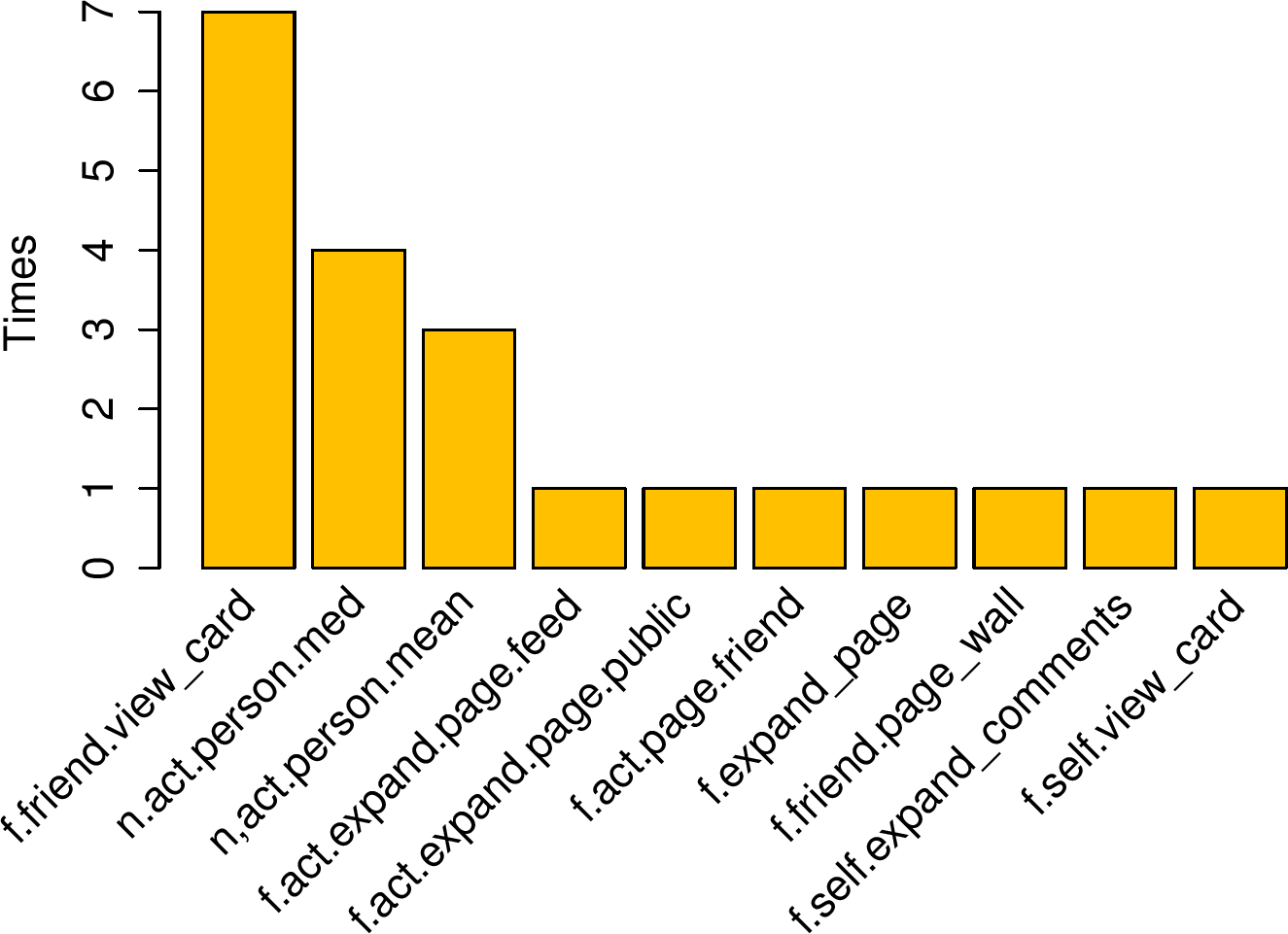 (a) Significant features for stalkers
(a) Significant features for stalkers
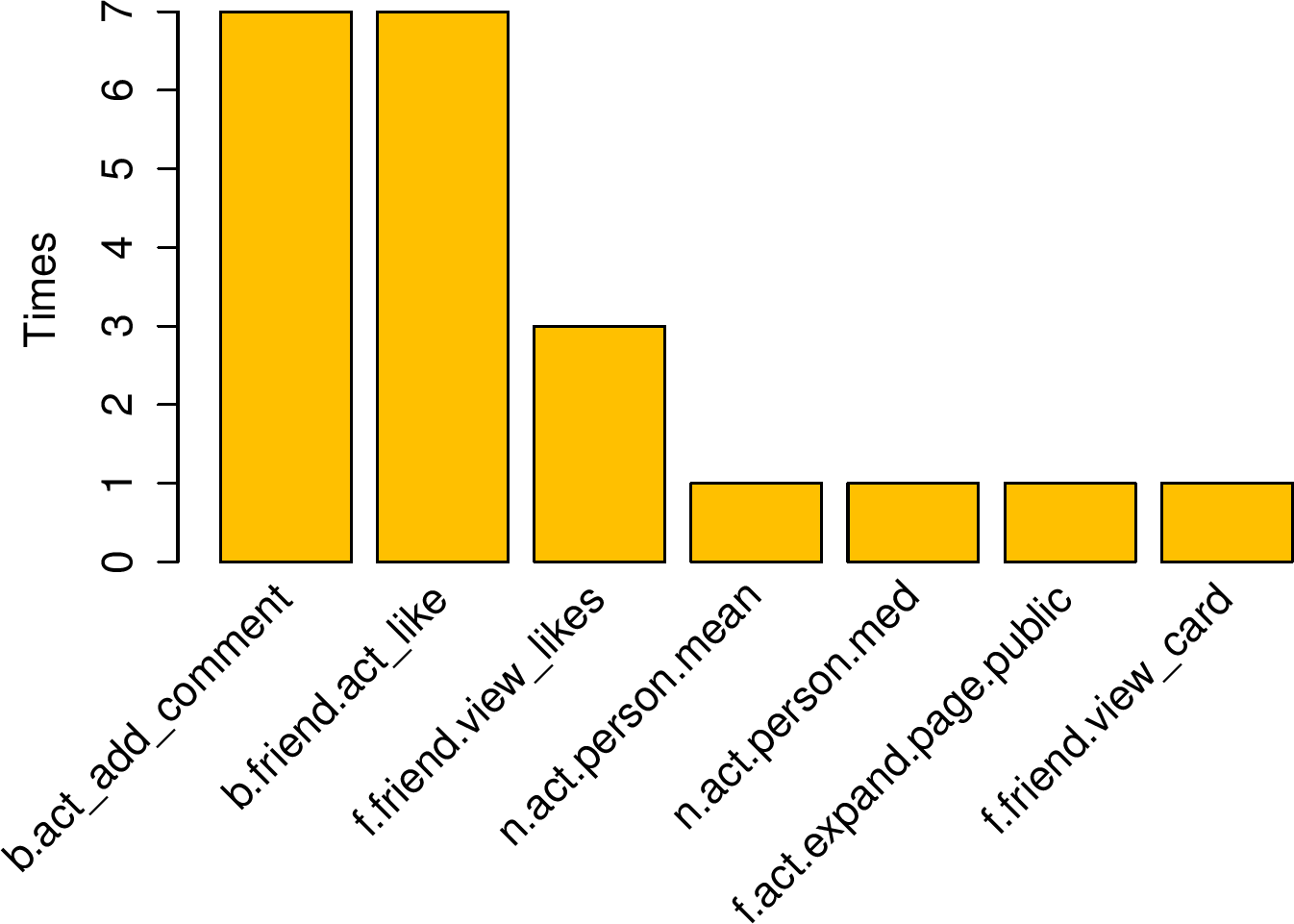 (b) Significant features for
account owners
(b) Significant features for
account owners