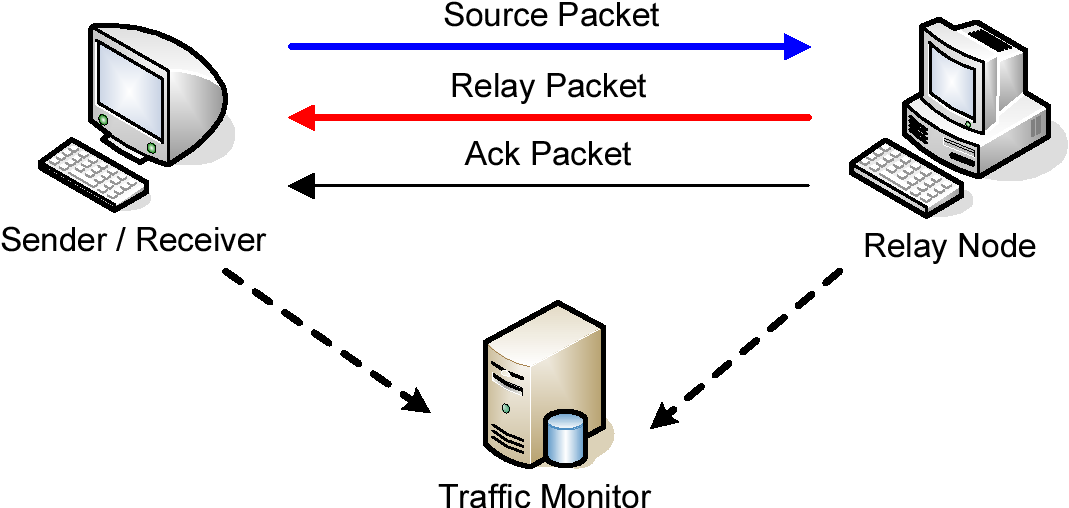
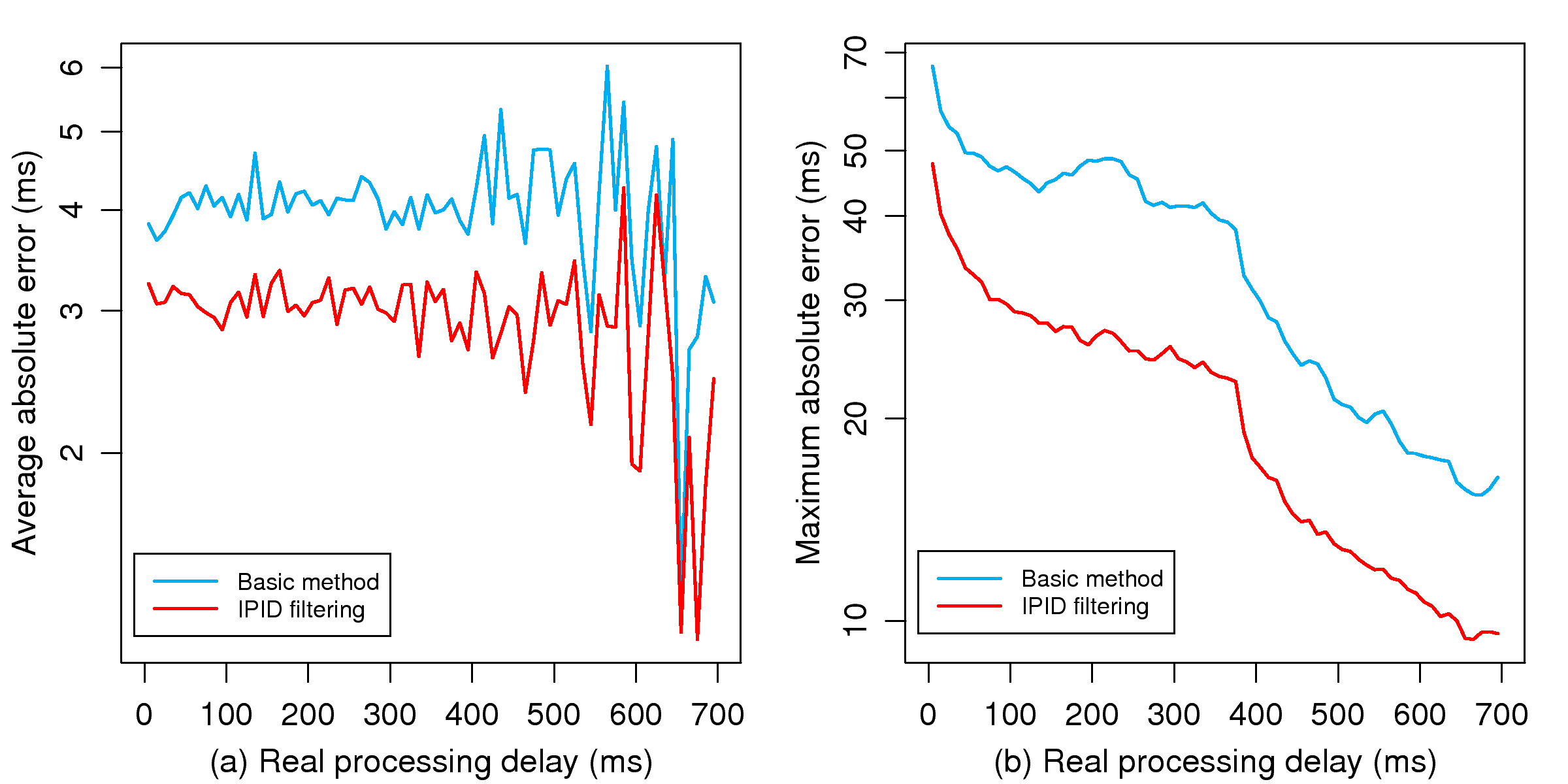
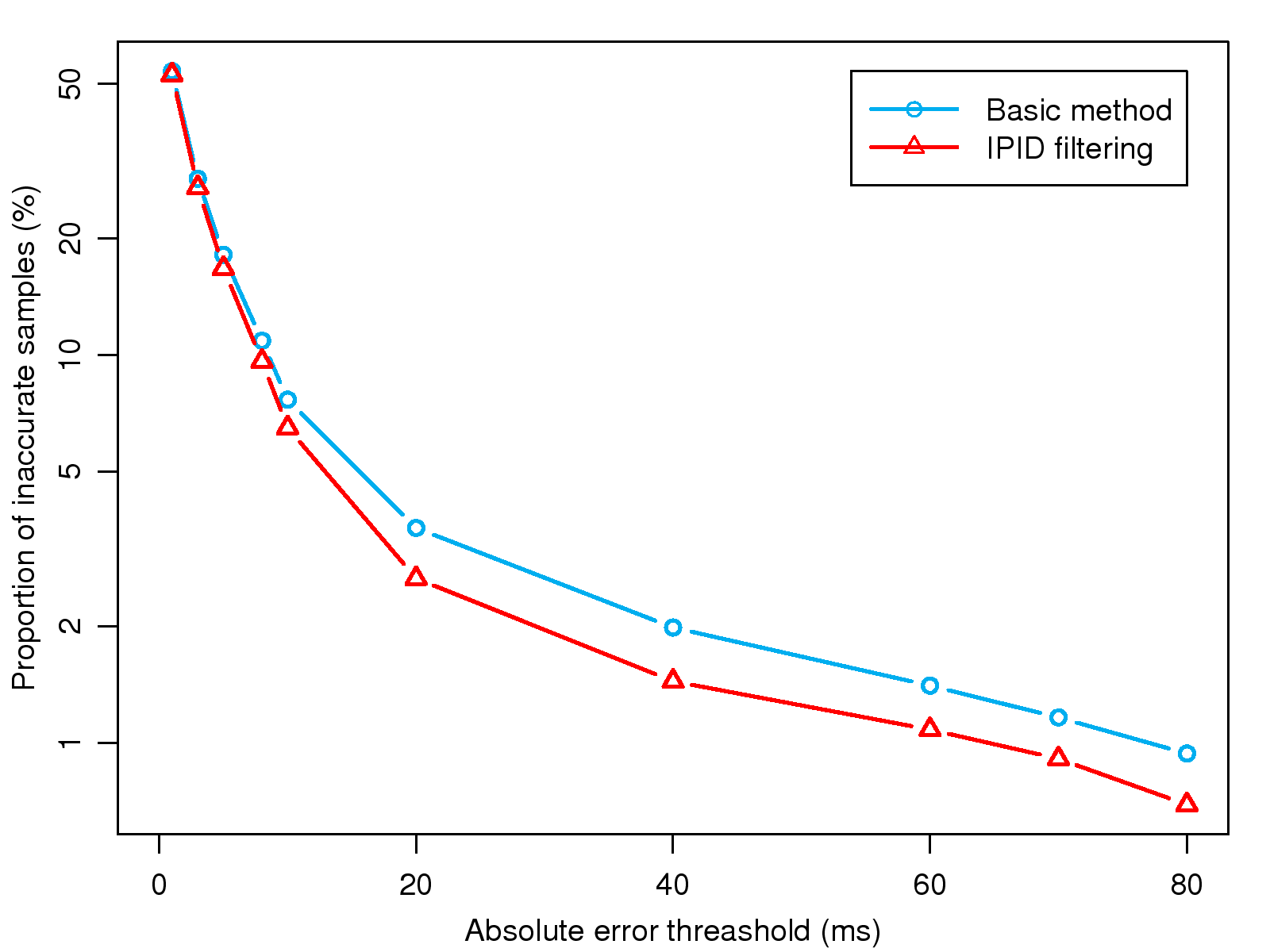
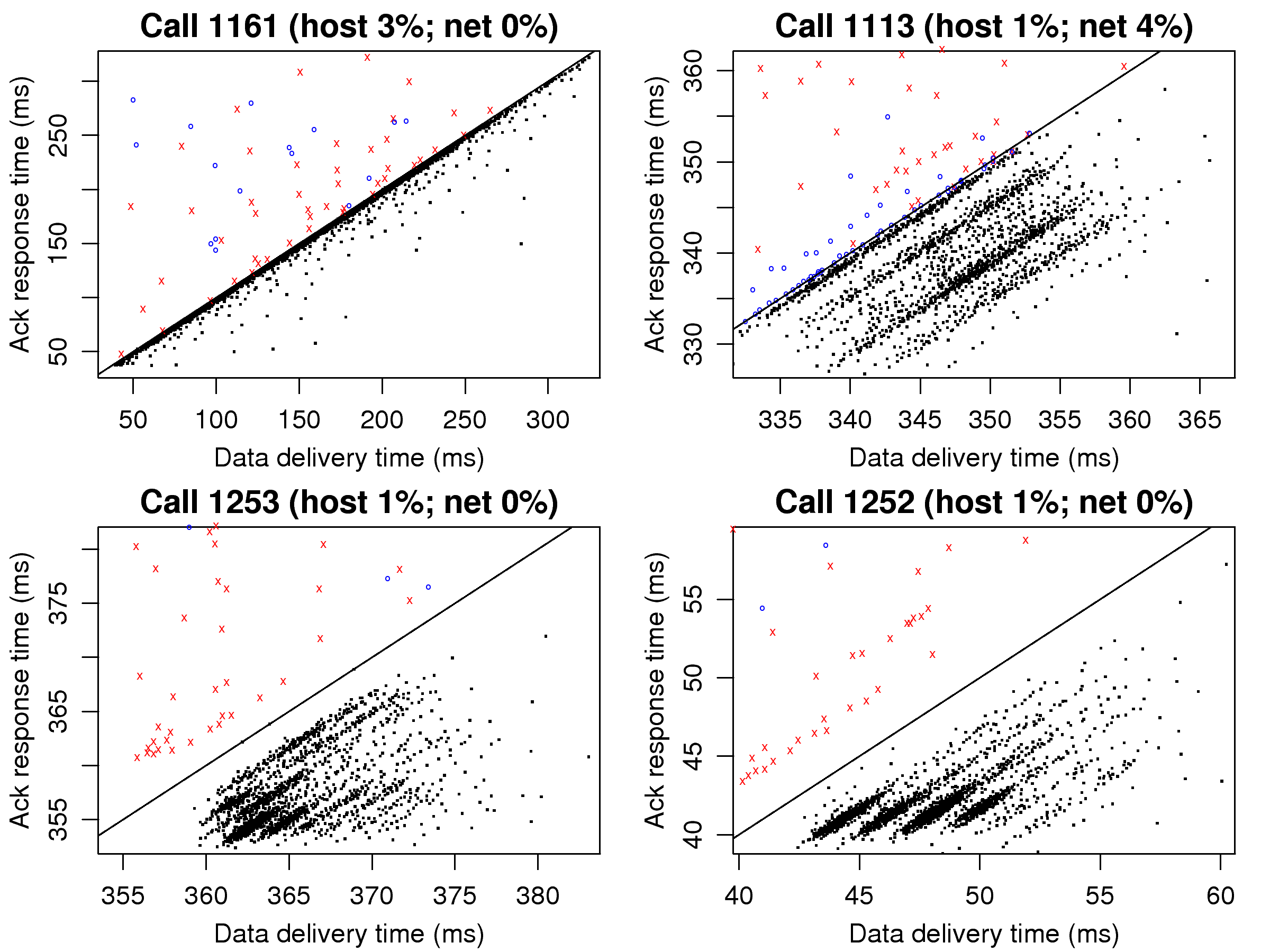
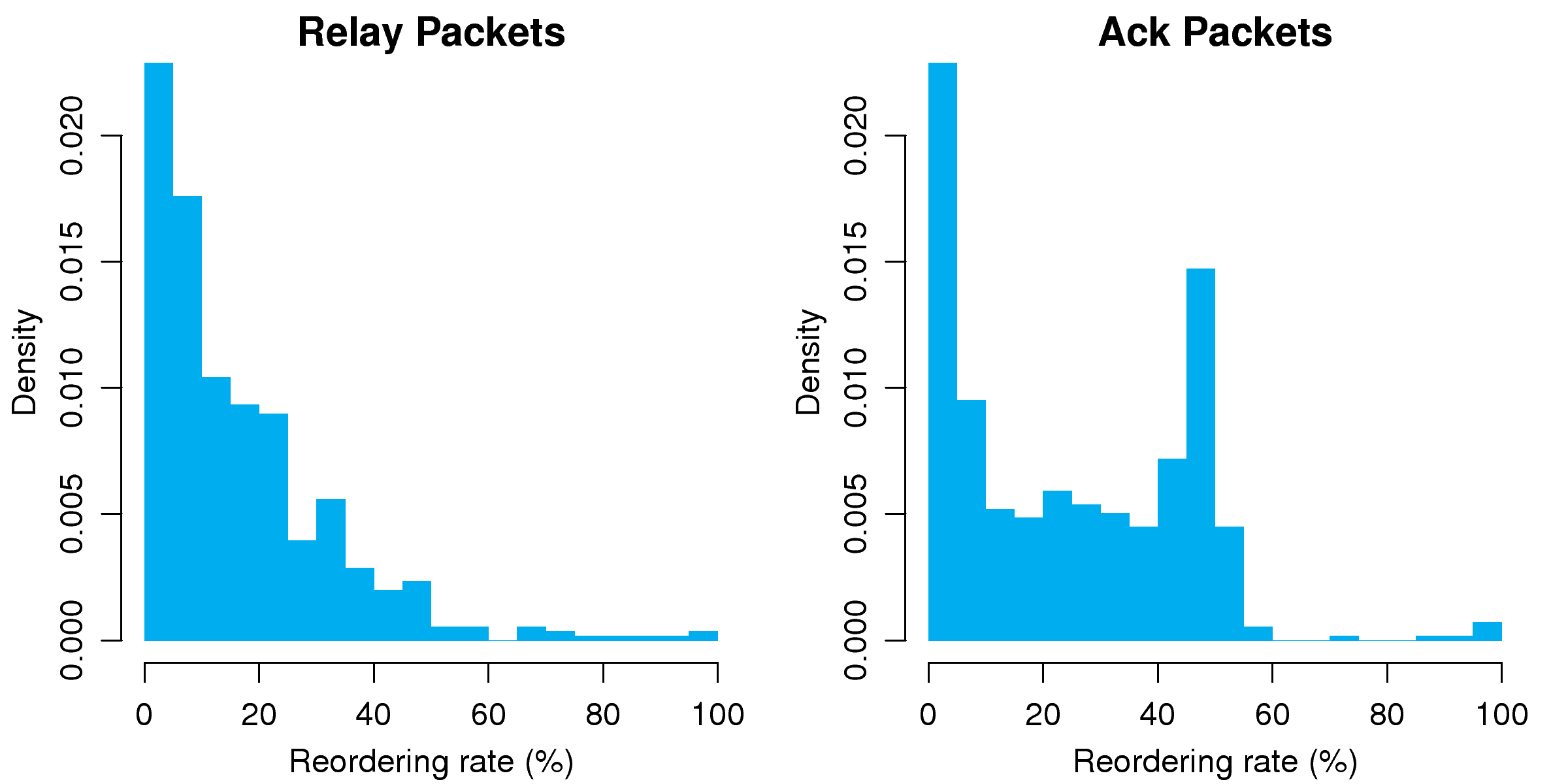
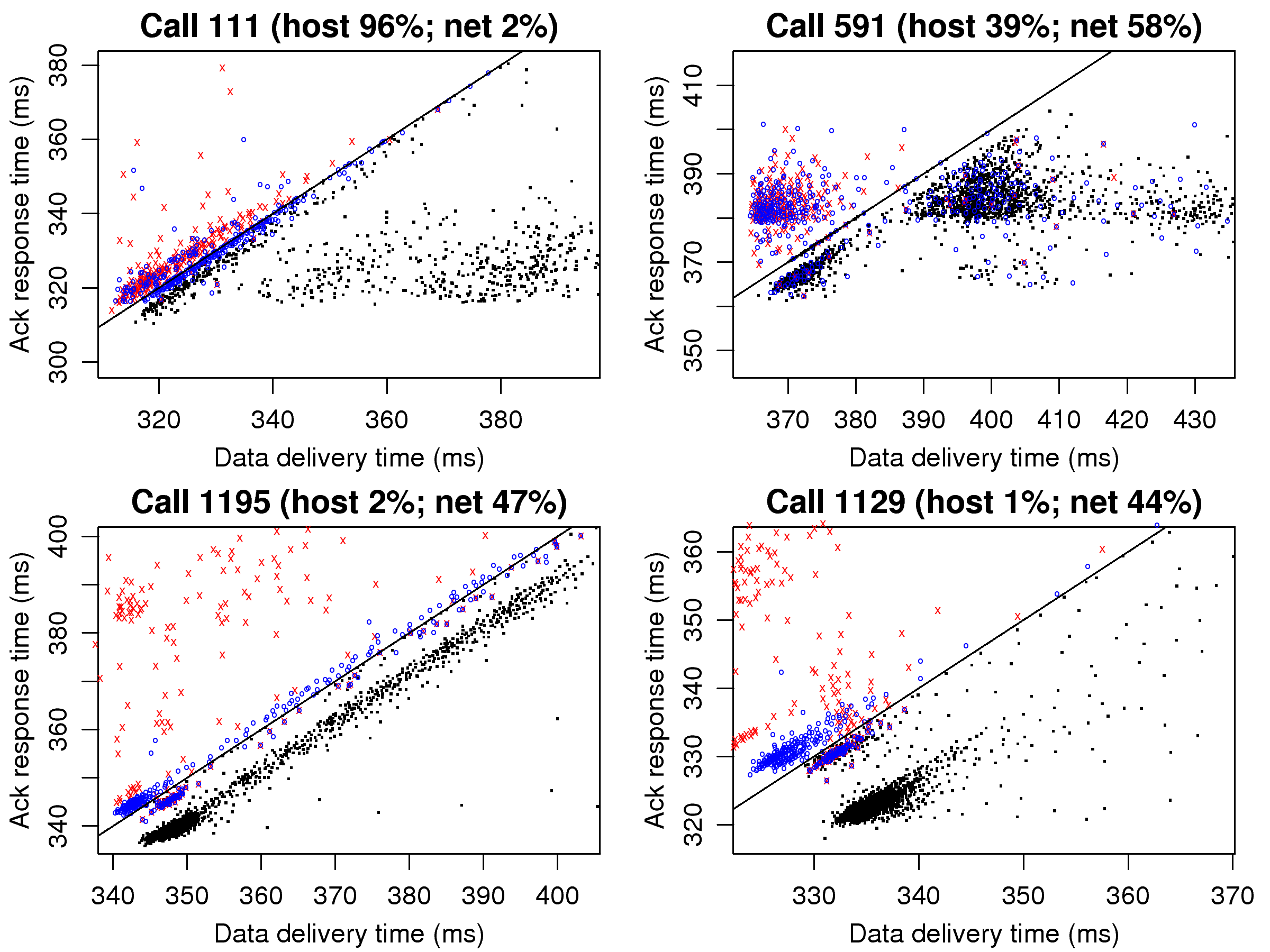
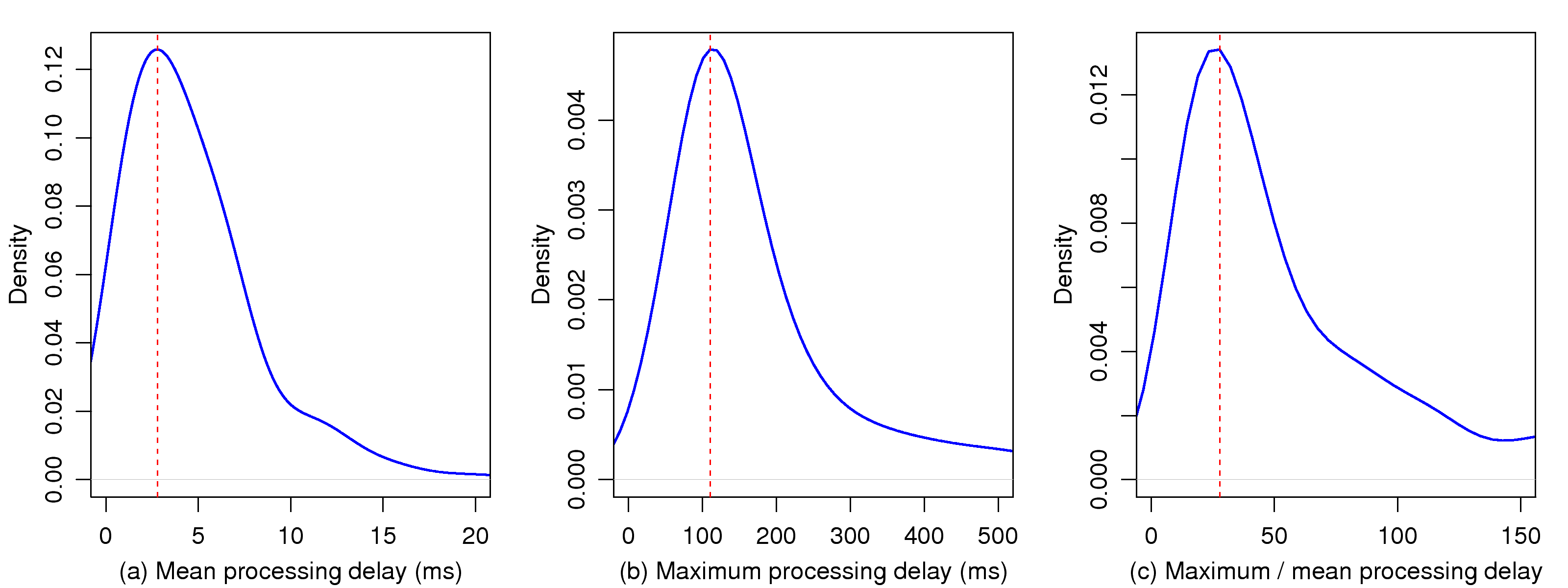
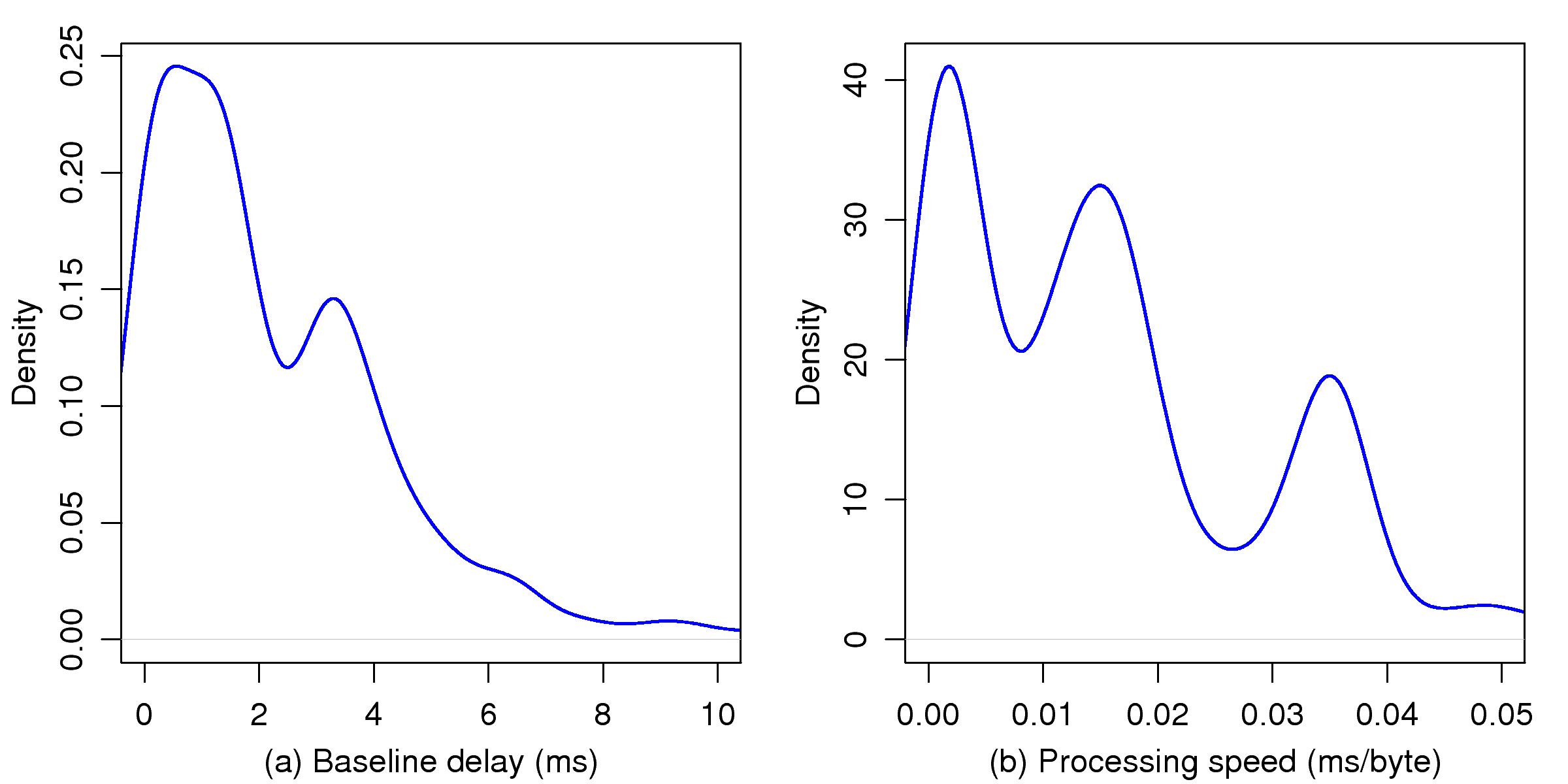
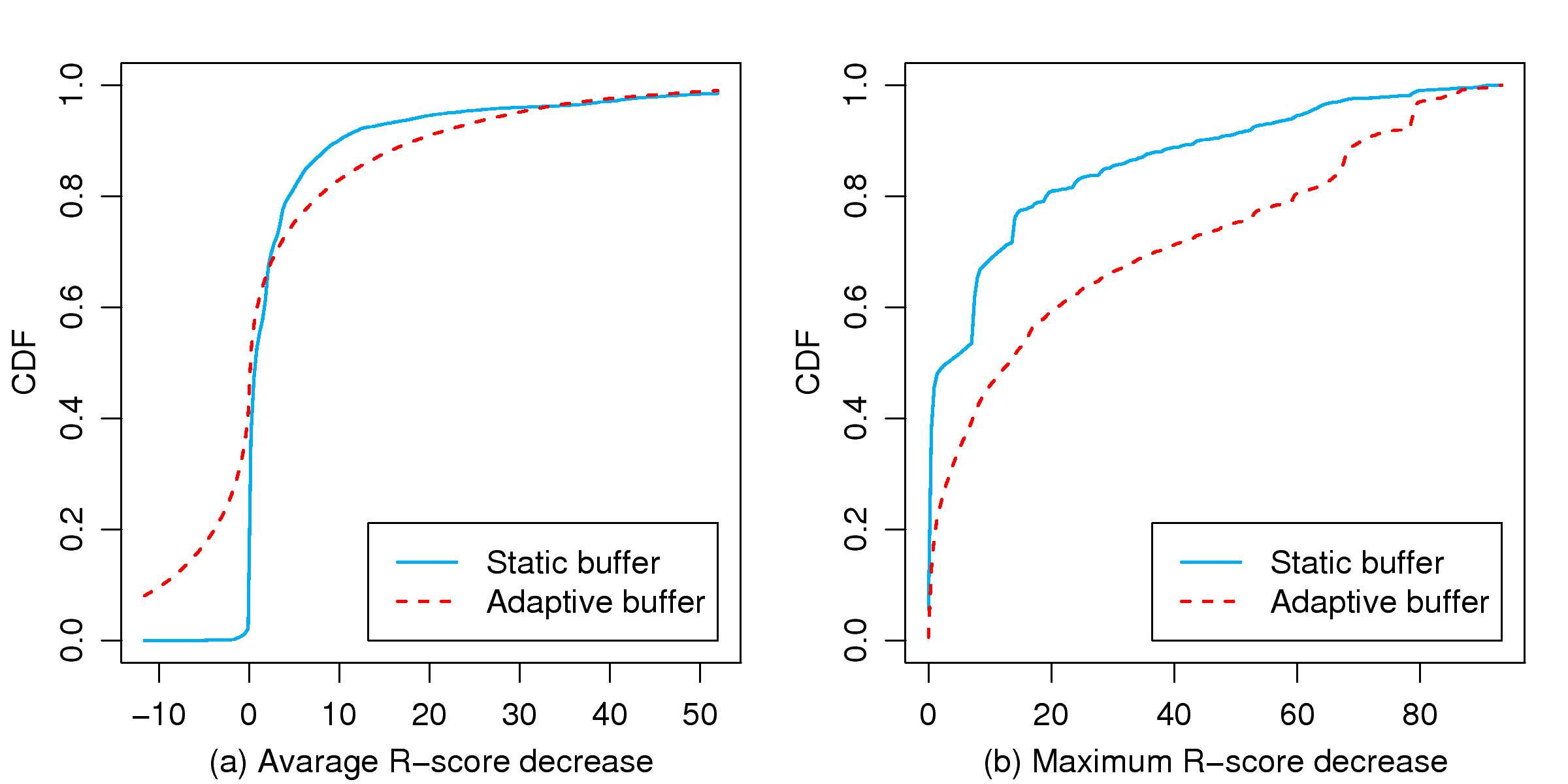
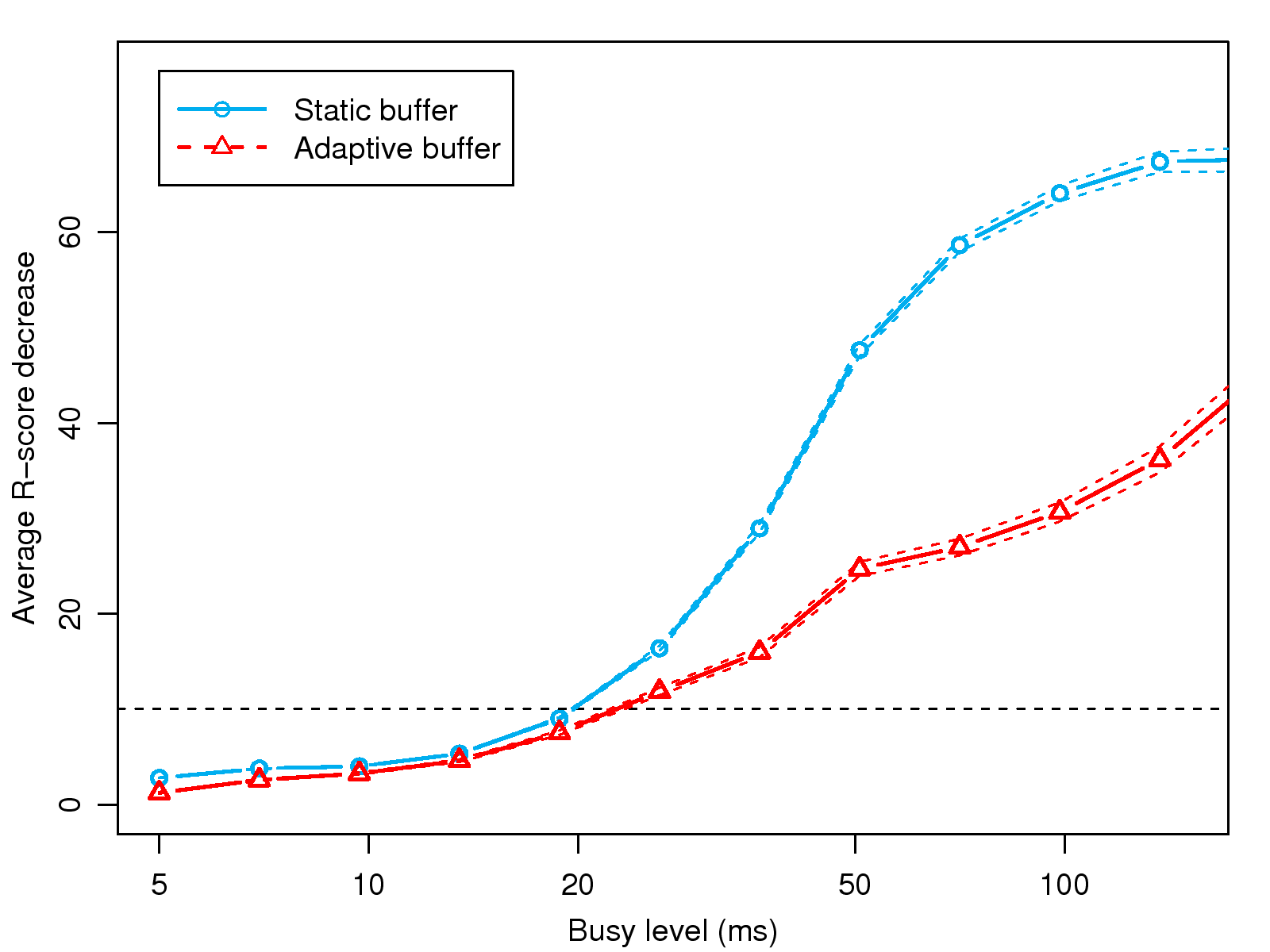
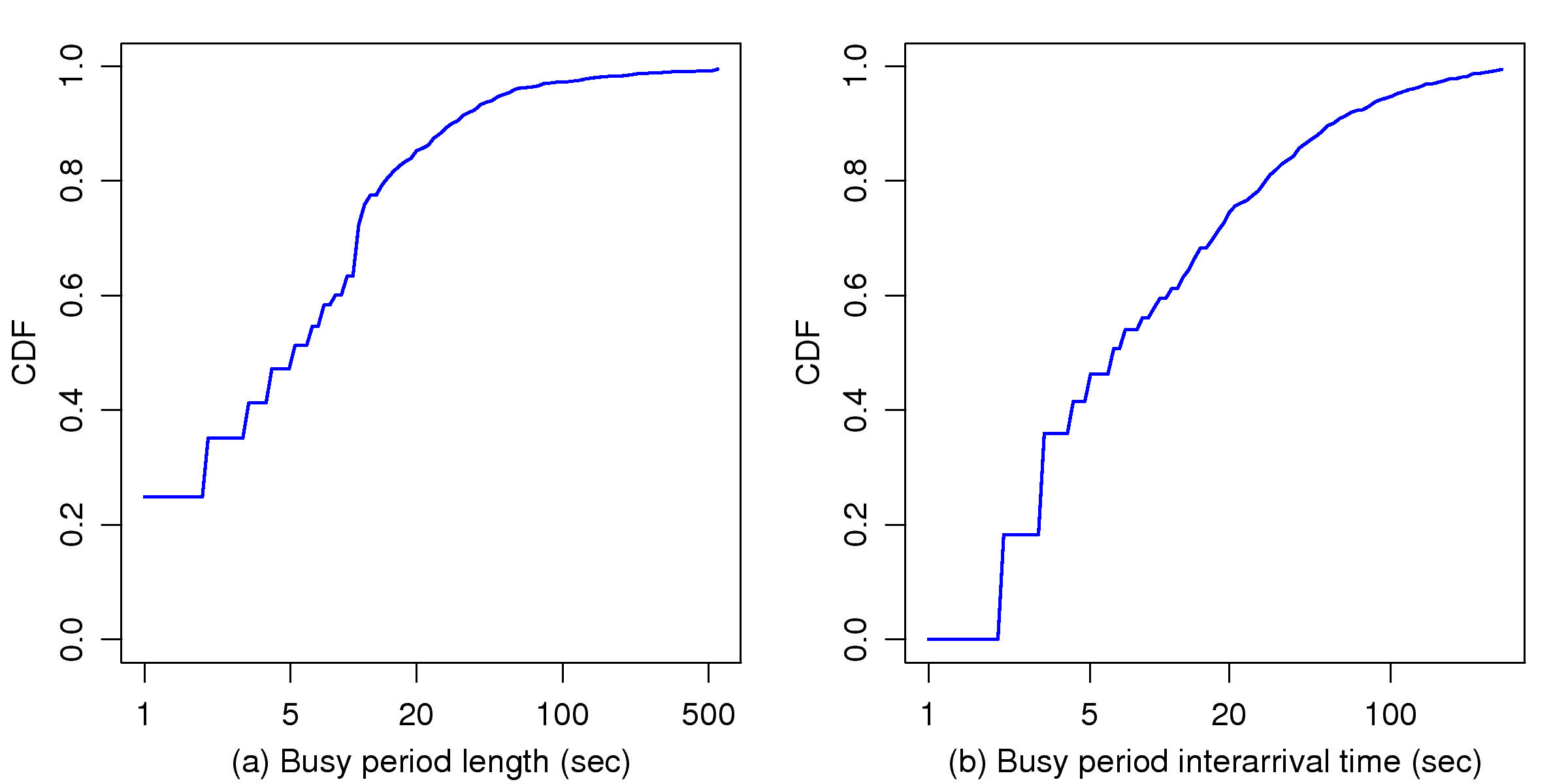
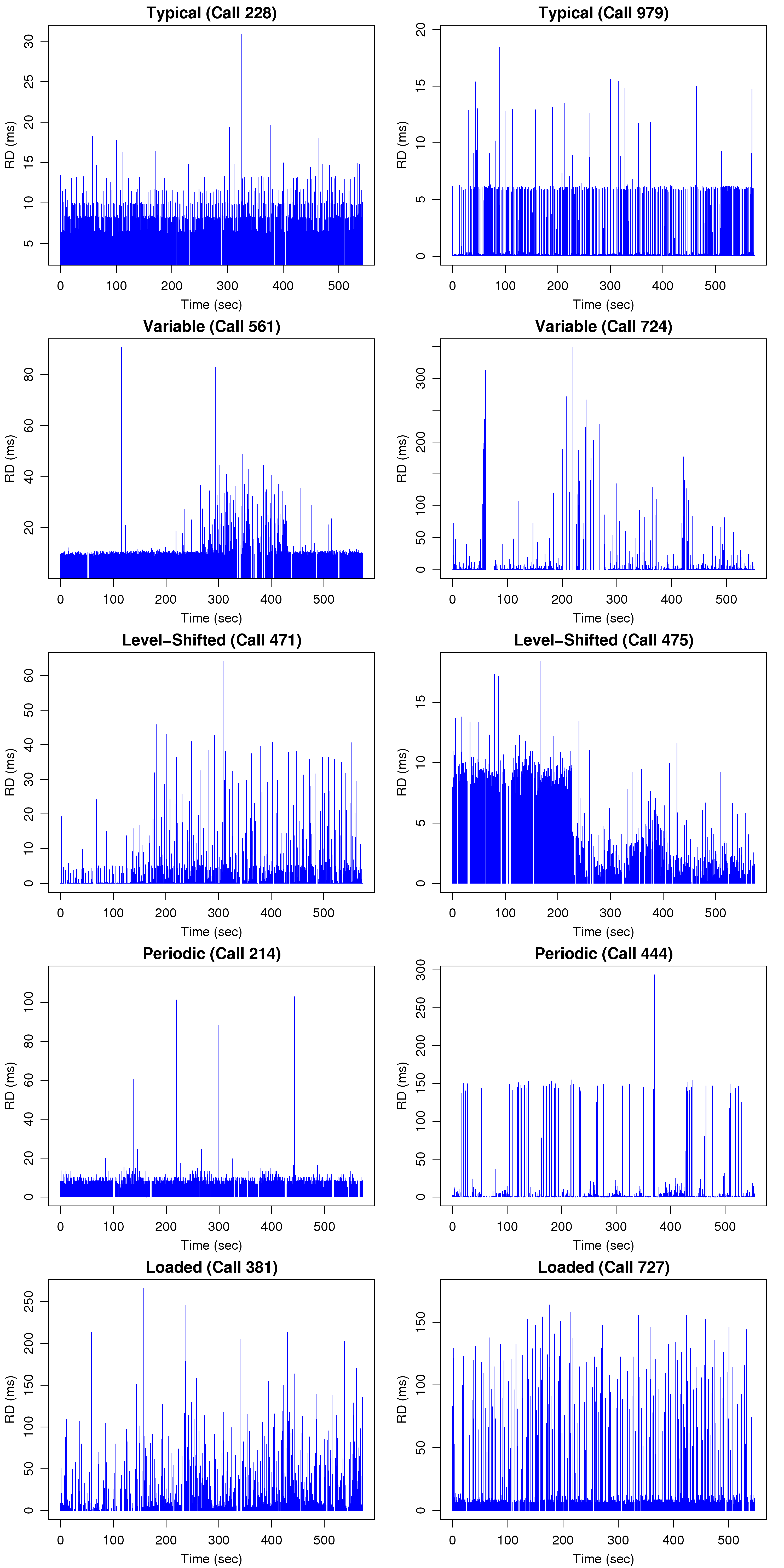
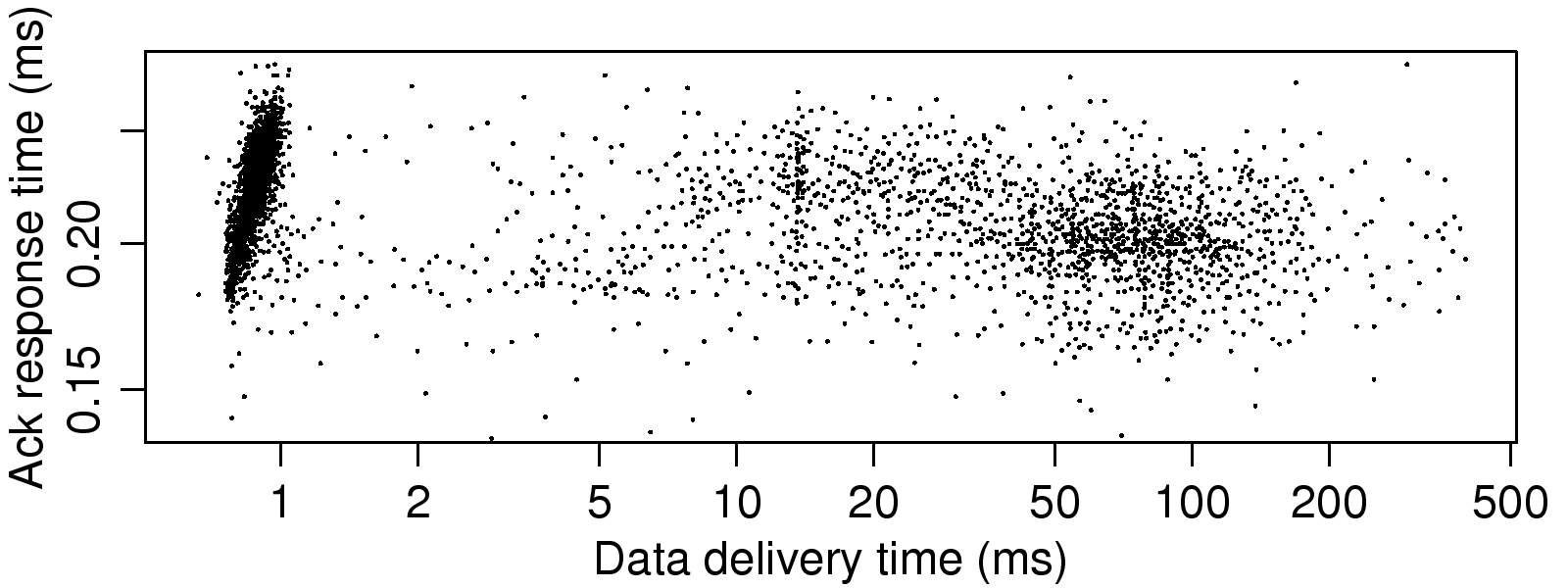
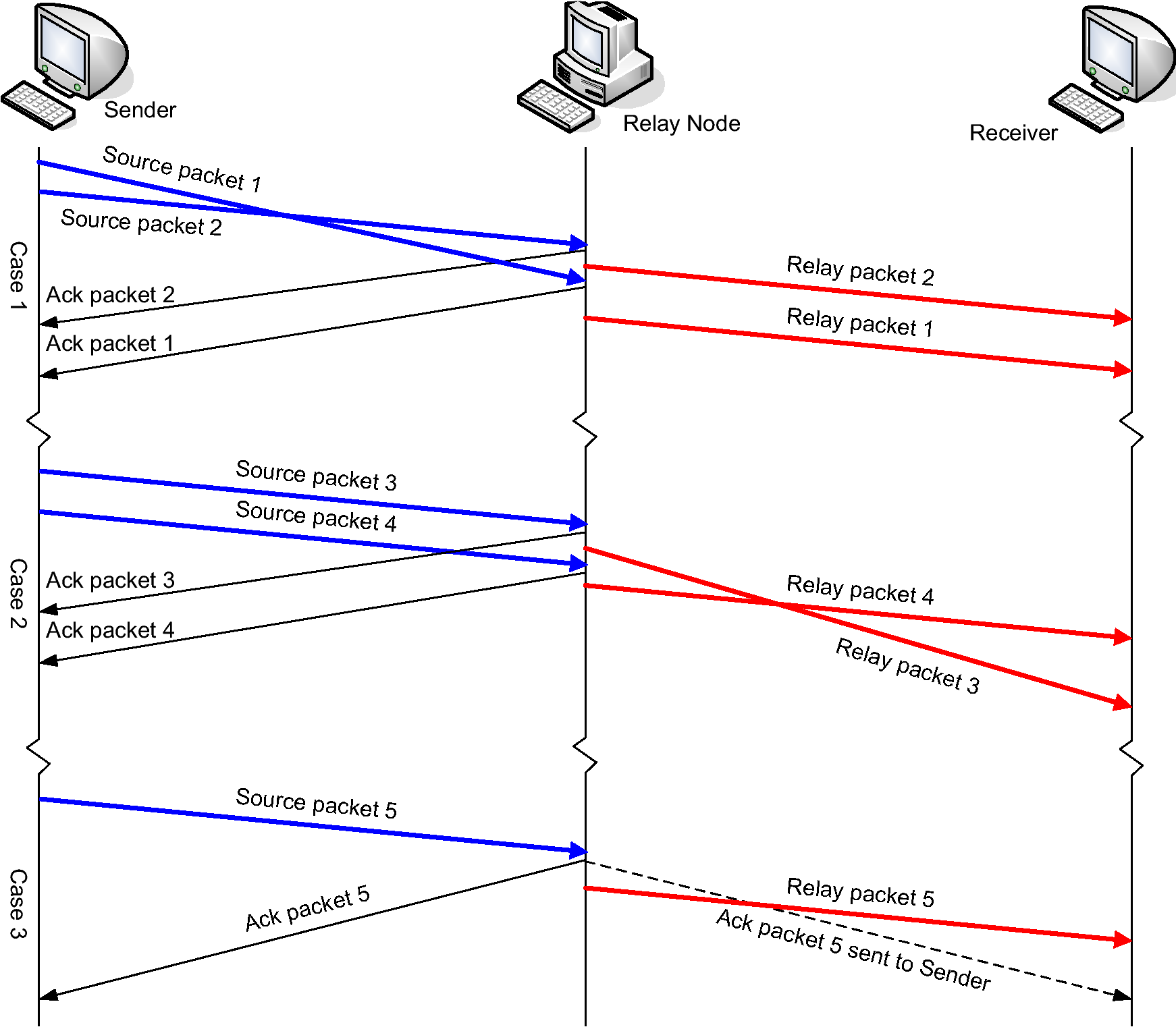
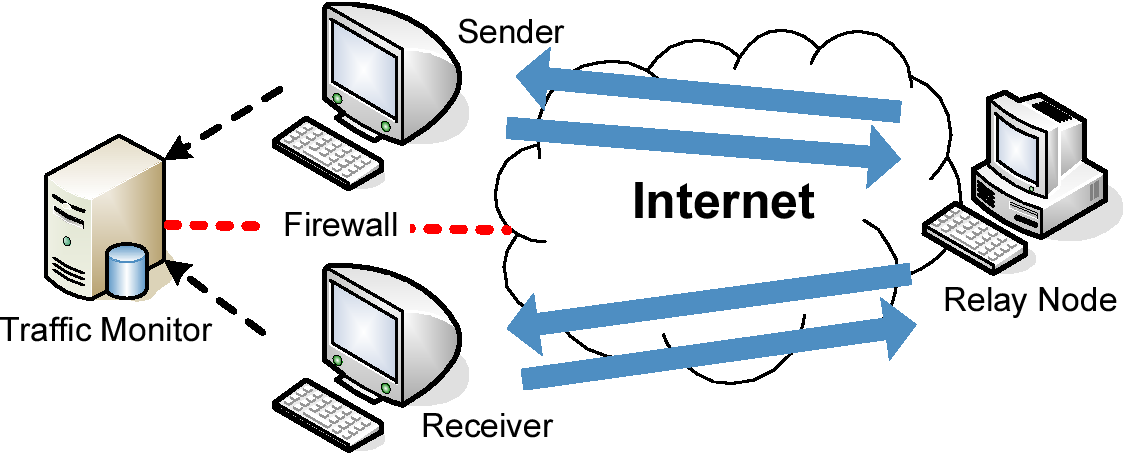
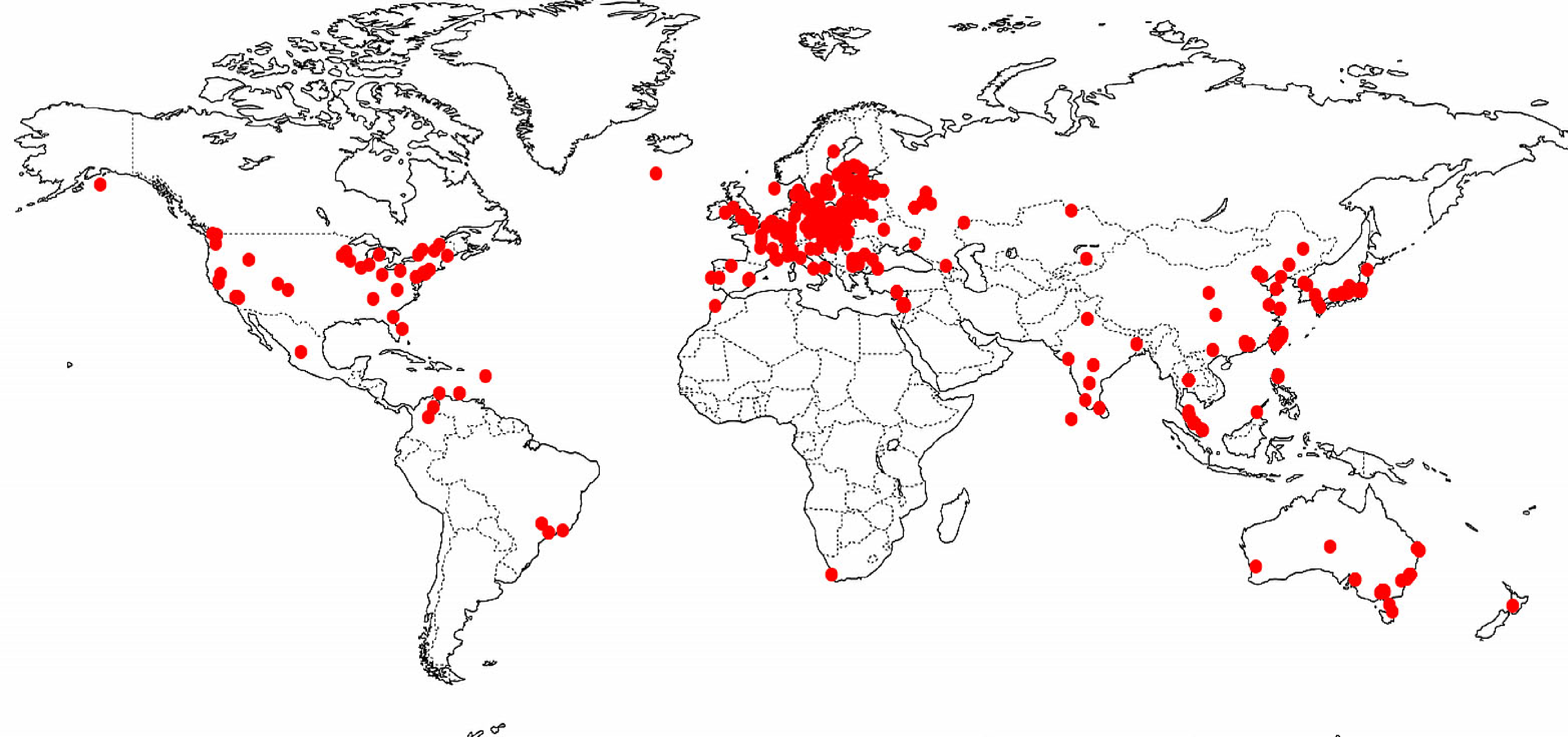
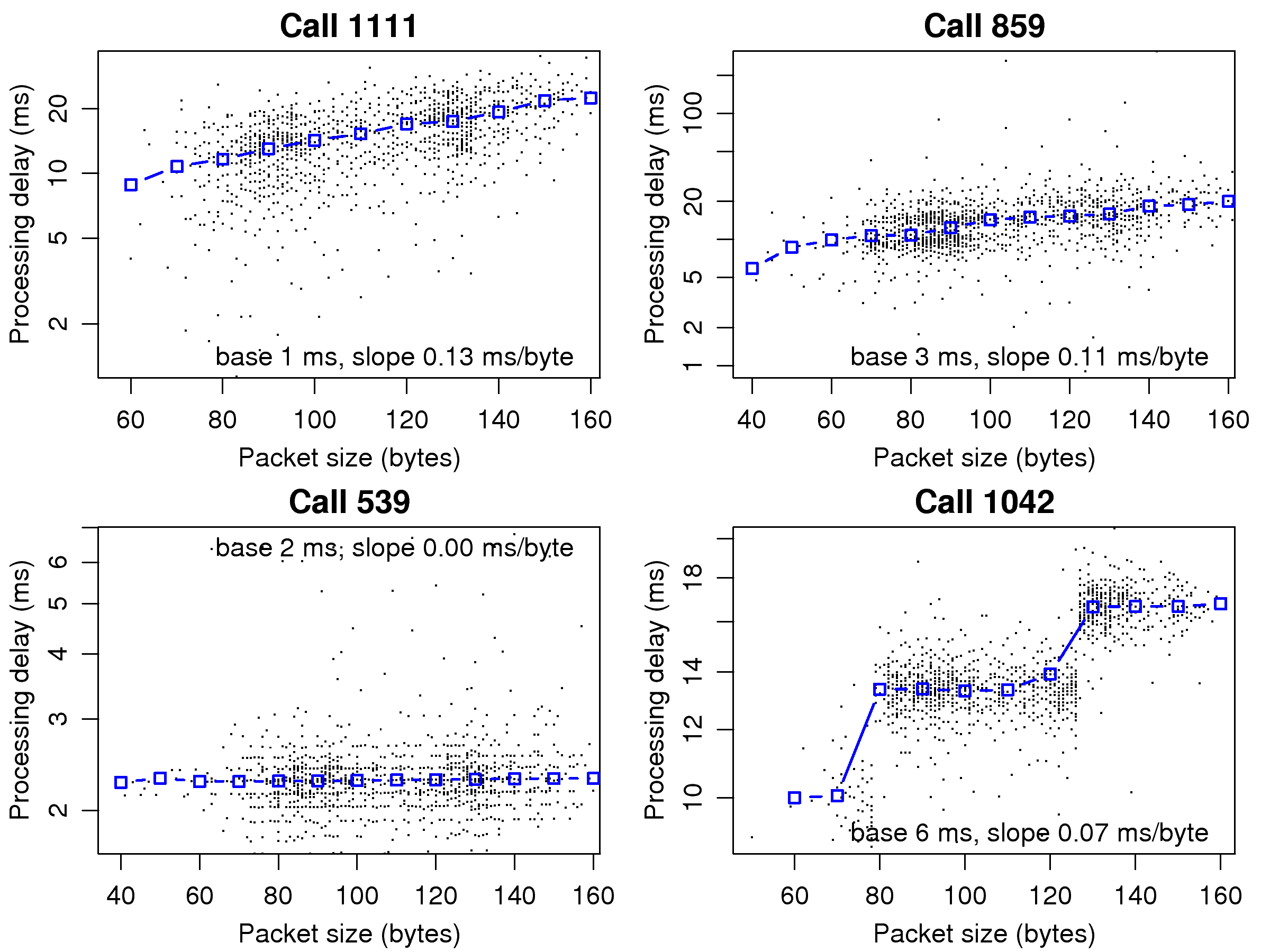
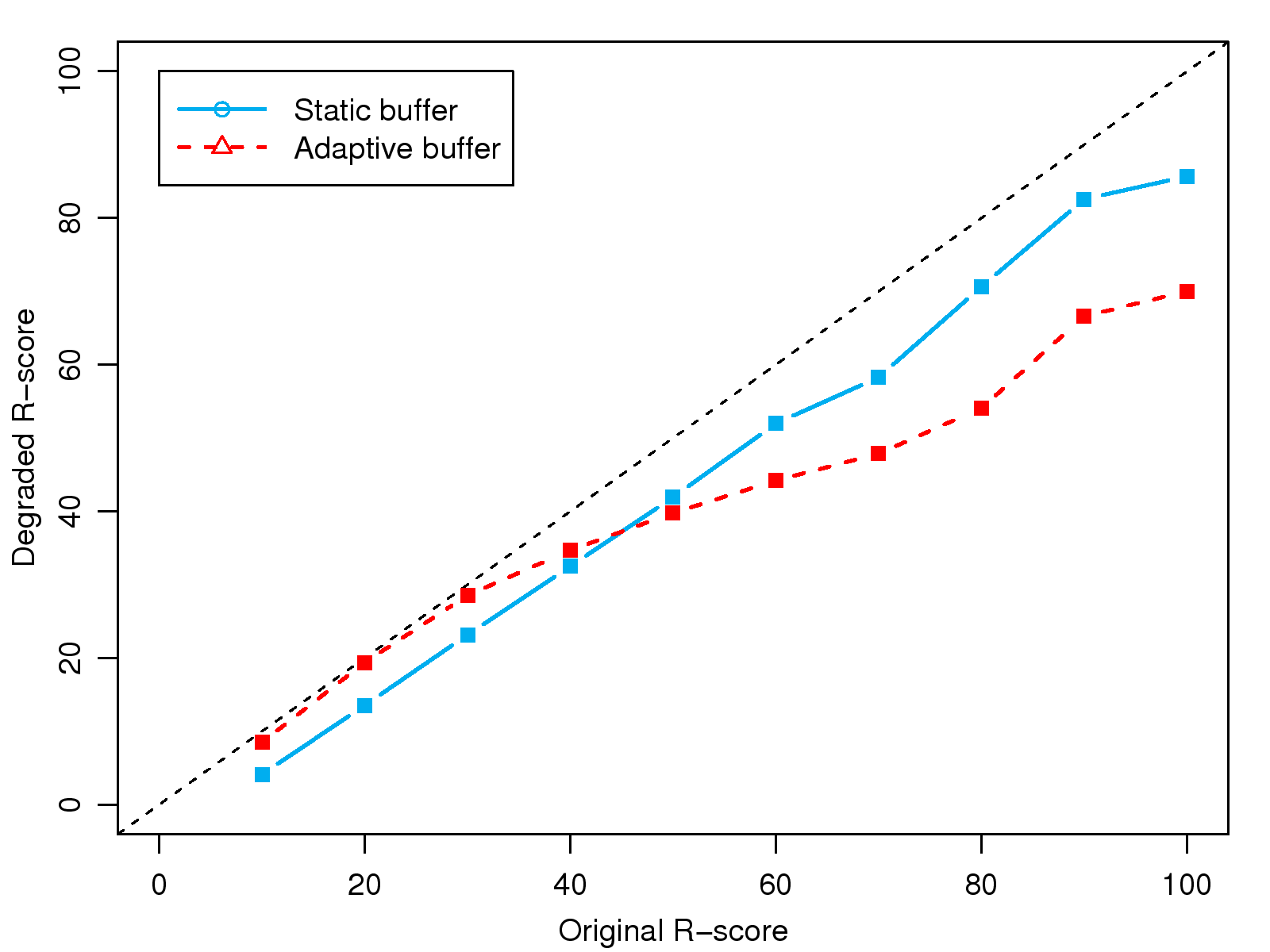
[1]
S. Baset and H. Schulzrinne, "An analysis of the Skype peer-to-peer internet
telephony protocol," in
INFOCOM. IEEE, 2006.
[2]
K.-T. Chen, C.-Y. Huang, P. Huang, and C.-L. Lei, "
Quantifying Skype User Satisfaction," in
Proceedings of ACM SIGCOMM 2006, Pisa Itlay, Sep
2006.
[3]
C.-M. Cheng, Y.-S. Huan, H. T. Kung, and C.-H. Wu, "Path probing relay routing
for achieving high end-to-end performance," in
Global
Telecommunications Conference, 2004. GLOBECOM '04. IEEE, vol. 3, 2004, pp.
1359-1365.
[4]
T. Fei, S. Tao, L. Gao, and R. Guérin, "How to select a good alternate
path in large peer-to-peer systems?" in
INFOCOM. IEEE, 2006.
[5]
T. Fei, S. Tao, L. Gao, R. Guérin, and Z.-L. Zhang, "Light-weight overlay
path selection in a peer-to-peer environment," in
INFOCOM. IEEE, 2006.
[6]
B. Ford, P. Srisuresh, and D. Kegel, "Peer-to-peer communication across
network address translators," in
USENIX Annual Technical Conference,
2005, pp. 179-192.
[7]
Google, Inc.,
http://www.google.com/talk/.
[8]
S. Guha and N. Daswani, "
_US
An experimental study of
the Skype peer-to-peer VoIP system," Cornell University, Tech. Rep.,
Dec. 16 2005.
[9]
F. Gustafsson,
Adaptive Filtering and Change Detection. John Wiley & Sons, September 2000.
[10]
X. Hei, C. Liang, J. Liang, Y. Liu, and K. Ross, "A Measurement Study of a
Large-Scale P2P IPTV System," in
IPTV Workshop, International World
Wide Web Conference, 2006.
[11]
X. Hei and H. Song, "Stochastic relay routing in peer-to-peer networks," in
Proceedings 41st IEEE International Conference on Communications,
2006.
[12]
ITU-T Recommandation, "G. 107. The E-Model, a Computational Model for Use
in Transmission Planning," International Telecommunication Union, CHGenf,
2002.
[13]
X. Liao, H. Jin, Y. Liu, L. M.Ni, and D. Deng, "Anysee: Peer-to-peer live
streaming," in
INFOCOM. IEEE,
2006.
[14]
L. Liu and R. Zimmermann, "Adaptive low-latency peer-to-peer streaming and its
application,"
Multimedia Systems, vol. 11, no. 6, pp. 497-512, 2006.
[15]
Y. Liu, Y. Gu, H. Zhang, W. Gong, and D. Towsley, "Application level relay for
high-bandwidth data transport," in
The First Workshop on Networks for
Grid Applications (GridNets), San Jose, October 2004.
[16]
A. Markopoulou, F. A. Tobagi, and M. J.Karam, "Assessment of voIP quality
over internet backbones," in
Proceedings of INFOCOM, 2002.
[17]
S. McCanne and V. Jacobson, "The BSD packet filter: A new architecture for
user-level packet capture," in
Proceedings of USENIX'93, 1993, pp.
259-270.
[18]
J. Nagle, "Congestion control in IP/TCP internetworks,"
Computer
Communication Review, vol. 14, no. 4, pp. 11-17, Oct. 1984.
[19]
M. Narbutt, A. Kelly, L. Murphy, and P. Perry, "Adaptive voIP playout
scheduling: Assessing user satisfaction,"
IEEE Internet Computing,
vol. 9, no. 4, pp. 28-34, 2005.
[20]
V. Paxson and S. Floyd, "Wide-area traffic: The failure of poisson modeling,"
in
SIGCOMM, 1994, pp. 257-268.
[21]
R. Ramaswamy, N. Weng, and T. Wolf, "Characterizing network processing
delay," in
Proceeding of IEEE Global Communications Conference
(GLOBECOM), Dallas, TX, nov 2004.
[22]
R. Ramjee, J. F. Kurose, D. F.Towsley, and H. Schulzrinne, "Adaptive playout
mechanisms for packetized audio applications in wide-area networks," in
INFOCOM, 1994, pp. 680-688.
[23]
S. Ren, L. Guo, and X. Zhang, "ASAP: an AS-aware peer-relay protocol for
high quality voIP," in
Proceedings of ICDCS, 2006, pp. 70-79.
[24]
J. Rosenberg, R. Mahy, and C. Huitema, "Traversal Using Relay NAT (TURN),"
draft-rosenberg-midcom-turn-05 (work in progress), July, 2004.
[25]
B. Sat and B. W. Wah, "Playout scheduling and loss-concealments in voip for
optimizing conversational voice communication quality," in
Proceedings
of Multimedia'07. New York, NY, USA:
ACM, 2007, pp. 137-146.
[26]
C. Schensted, "Longest increasing and decreasing subsequences,"
Canad.
J. Math., vol. 13, pp. 179-191, 1961.
[27]
Skype Limited,
http://www.skype.com.
[28]
D. A. Solomon and M. Russinovich,
Inside Microsoft Windows 2000. Microsoft Press Redmond, WA, USA, 2000.
[29]
H. Zhang, L. Tang., and J. Li, "Impact of Overlay Routing on End-to-End
Delay," in
Proceedings of ICCCN, 2006, pp. 435-440.
[30]
Y. Zhang and N. G. Duffield, "On the constancy of internet path properties,"
in
Proceedings of Internet Measurement Workshop, V. Paxson, Ed. San Francisco, California, USA: ACM, Nov
2001, pp. 197-211.
[31]
R. Zimmermann, B. Seo, L. Liu, R. Hampole, and B. Nash, "Audiopeer: A
collaborative distributed audio chat system,"
Distributed Multimedia
Systems, San Jose, CA, 2004.