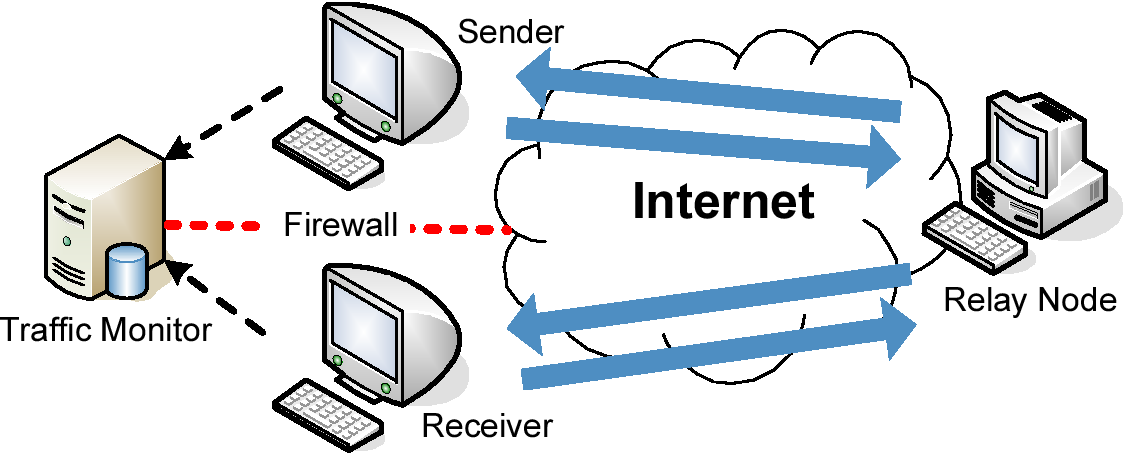
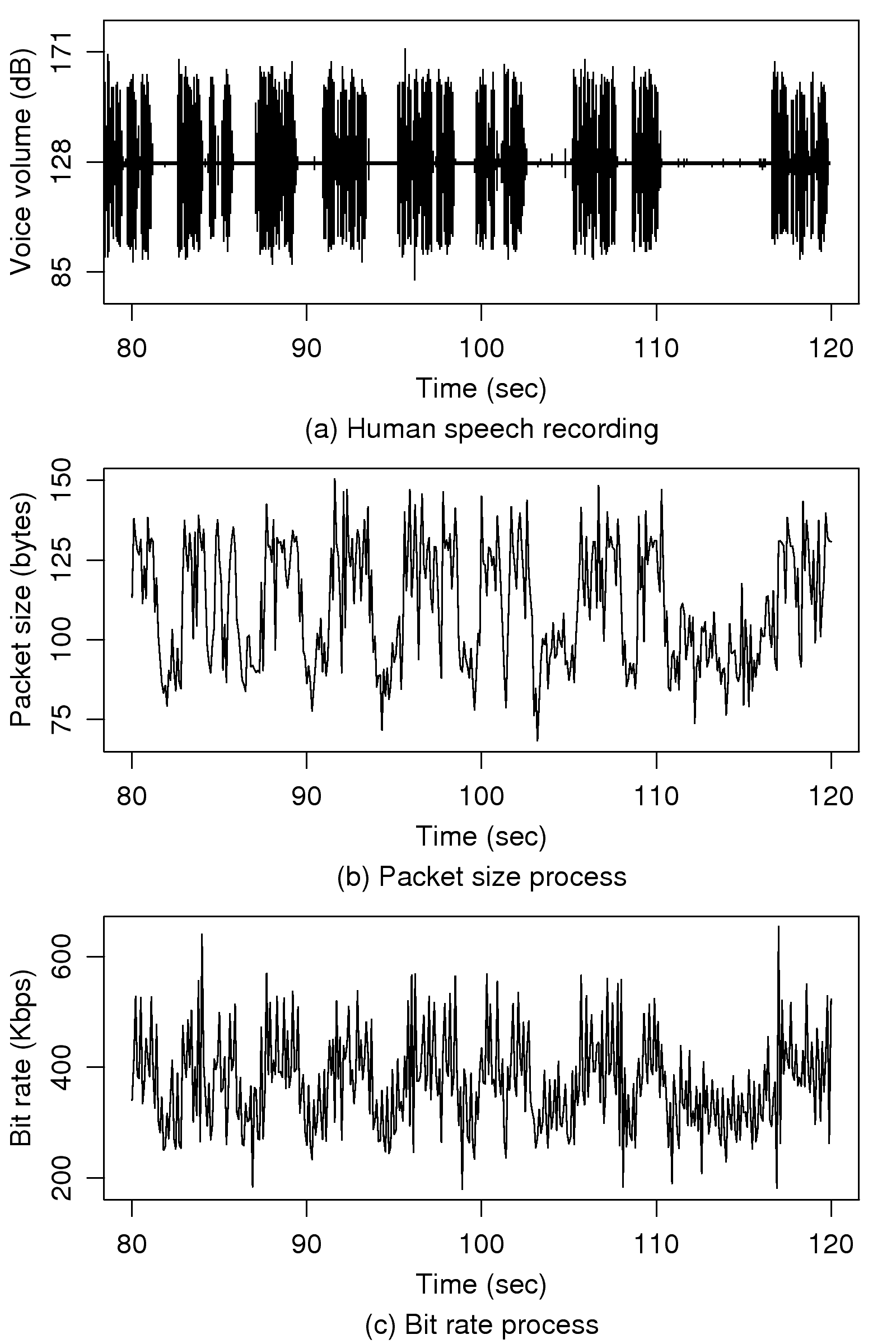
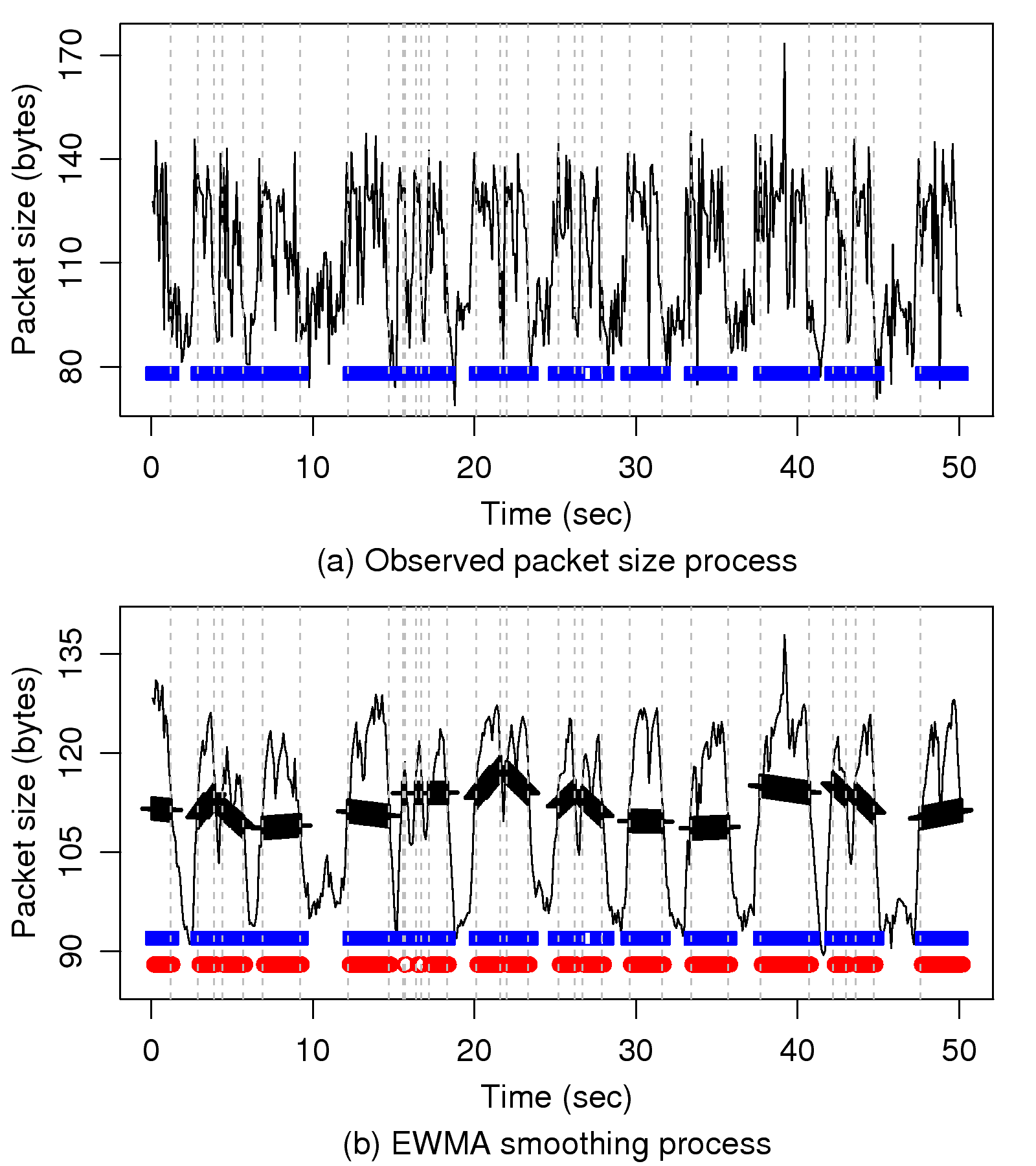
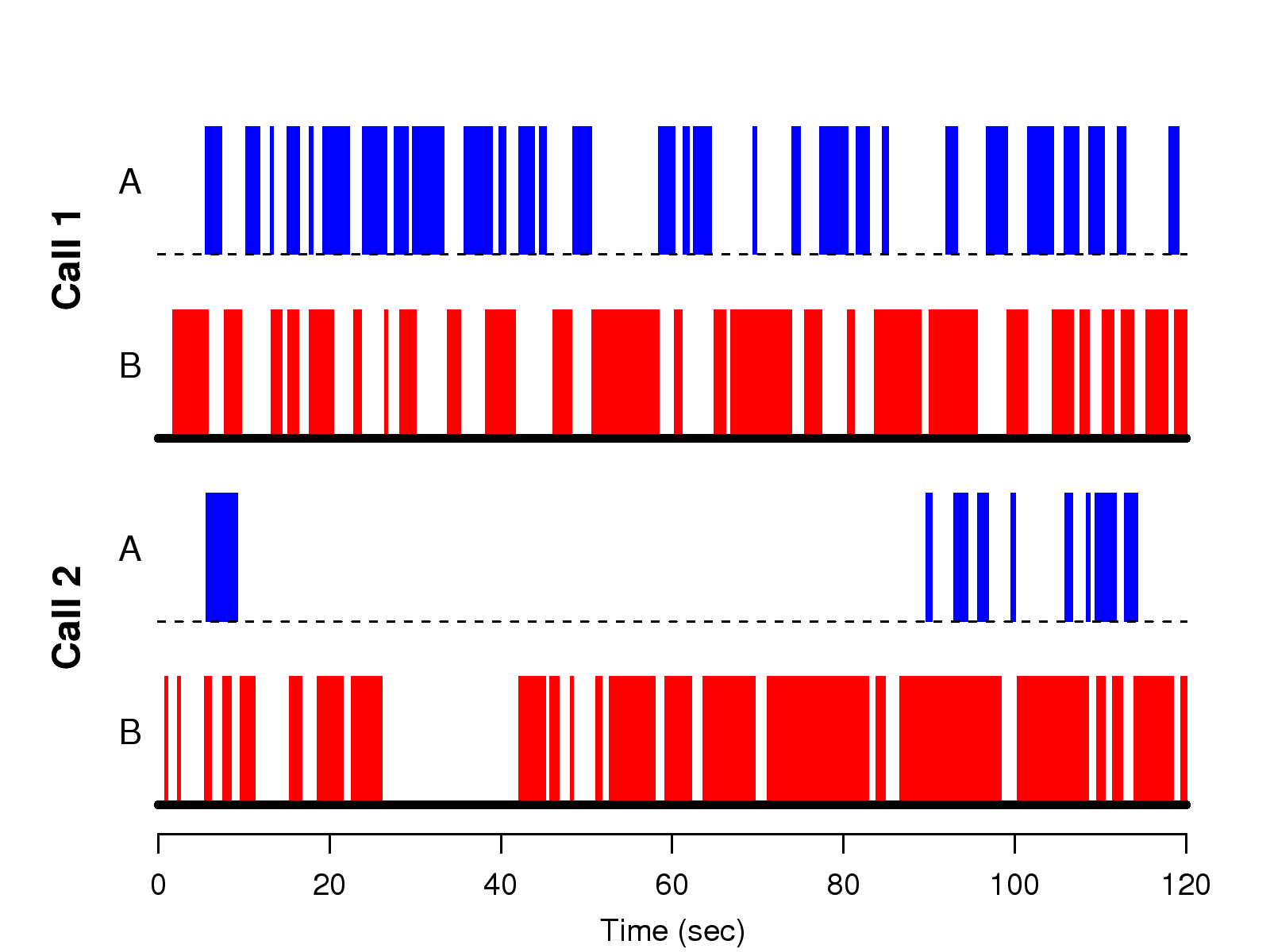
[1]
"Fine - tuning voice over packet services,"
http://www.protocols.com/papers/voip2.htm.
[2]
I. S. 802.16-2004, "Ieee standard for local and metropolitan area networks
part 16: Air interface for fixed broadband wireless access systems," Oct
2004.
[3]
R. Beuran, M. Ivanovici, B. Dobinson, N. Davies, and P. Thompson, "Network
quality of service measurement system for application requirements
evaluation," in
SPECTS'03. New
York, NY, USA: ACM, July 2003, pp. 380-387.
[4]
P. T. Brady, "A statistical analysis of on-off patterns in 16 conversations,"
Bell System Technical Journal, vol. 47, no. 1, Jan 1968.
[5]
K.-T. Chen, C.-Y. Huang, P. Huang, and C.-L. Lei, "
Quantifying Skype User Satisfaction," in
Proceedings of ACM SIGCOMM 2006, Pisa, Itlay, Sep
2006.
[6]
W. C. Feng, F. Chang, W. C. Feng, and J. Walpole, "A traffic characterization
of popular on-line games,"
IEEE/ACM Transactions on Networking,
vol. 13, no. 3, pp. 488-500, June 2005.
[7]
B. Francesco, C. Salvatore, and C. Alfredo, "A robust voice activity detector
for wireless communications using soft computing,"
IEEE Journal on
Selected Areas in Communications, vol. 16, no. 9, 1998.
[8]
F. Hammer, P. Reichl, and A. Raake, "The well-tempered conversation:
Interactivity, delay and perceptual voip quality," in
Proceedings IEEE
ICC'05, May 2005.
[9]
J. Hoyt and H. Wechsler, "Detection of human speech in structured noise," in
Proceedings of ICASSP '94, vol. ii. ACM Press, 1994, pp. 237-240.
[10]
J.-S. R. Jang, "Audio signal processing and recognition,"
http://www.cs.nthu.edu.tw/ jang.
[11]
S. Jongseo and S. Wonyong, "A voice activity detector employing soft decision
based noise spectrum adaptation," in
Proceedings of ICASSP '98, 1998,
pp. 365-368.
[12]
T. Karagiannis, K. Papagiannaki, and M. Faloutsos, "Blinc: multilevel traffic
classification in the dark,"
SIGCOMM Comput. Commun. Rev., vol. 35,
no. 4, pp. 229-240, 2005.
[13]
P. V. Marsden, "Network data and measurement,"
Annual Review of
Sociology, vol. 16, no. 1, pp. 435-463, 1990.
[14]
A. W. Moore and D. Zuev, "Internet traffic classification using bayesian
analysis techniques," in
SIGMETRICS '05: Proceedings of the 2005 ACM
SIGMETRICS international conference on Measurement and modeling of computer
systems. New York, NY, USA: ACM,
2005, pp. 50-60.
[15]
V. Prasad, M. R., S. Vijay, H. Shankar, P. Pawelczak, and I. Niemegeers,
"Voice activity detection for voip-an information theoretic approach," in
Proceedings of GLOBECOM '06, vol. ii. ACM Press, 2006.
[16]
L. Rabiner and M. Sambur, "Voiced-unvoiced-silence detection using the itakura
lpc distance measure," in
Proceedings of ICASSP '77, May. 1977, pp.
323-326.
[17]
P. Reichl and F. Hammer, "Hot discussion or frosty dialogue? towards a
temperature metric for conversational interactivity," in
ICSLP/INTERSPEECH 2004, Oct 2004.
[18]
M. Roughan, S. Sen, O. Spatscheck, and N. Duffield, "Class-of-service mapping
for qos: a statistical signature-based approach to ip traffic
classification," in
IMC '04: Proceedings of the 4th ACM SIGCOMM
conference on Internet measurement.
New York, NY, USA: ACM, 2004, pp. 135-148.
[19]
L. Sun and E. Ifeachor, "Prediction of perceived conversational speech quality
and effects of playout buffer algorithms,"
Communications, 2003. ICC
'03. IEEE International Conference on, vol. 1, pp. 1-6 vol.1, 11-15 May
2003.
[20]
I. T. Union, "Artificial conversational speech," March 1993, iTU-T
Recommendation P.59.
[21]
N. B. Yoma, F. McIness, and M. Jack, "Robust speech pulse-detection using
adaptive noise modeling,"
Electron. Lett., vol. 32, July 1996.