Page 43 - My FlipBook
P. 43
Brochure 2020
基於鑑別式自動編碼器之語者辨識及語音辨識
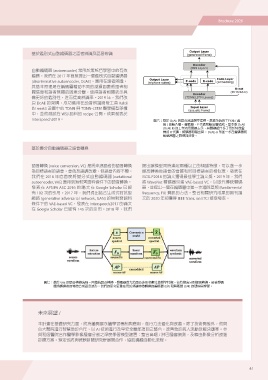
自動編碼器 (autoencoder) 常用於無監督學習中的有效 圖六:基於 DcAE 的語音辨識聲學建模。基線系統的工作流 ( 虛
編碼。我們在 2017 年首度提出一個鑑別式自動編碼器 線 ) 由輸入層、編碼器、P 代碼和輸出層組成。基本版 DcAE
(discriminative autoencoder, DcAE),應用在語者辨識, (DcAE-B) 的工作流用實線表示,其關鍵組件多了用於特徵重
其基本原理是在編碼層藉助不同的減損函數將語者相 構的 R 代碼、解碼器和輸出層。 DcAE-U 則進一步在編碼器和
關信息和語者無關的因素分離,使得語者相關表示具 解碼器層之間增加連接。
備更好的鑑別性,進而提高辨識率。2019 年,我們改
良 DcAE 的架構,成功套用在語音辨識開發工具 Kaldi
的 nnet3 設置中的 TDNN 與 TDNN-LSTM 聲學模型架構
中,並將測試在 WSJ 語料的 recipe 公開。成果發表於
Interspeech2019。
基於變分自動編碼器之語音轉換
語音轉換 (voice conversion, VC) 是將來源語者的語音轉換 提出讓模型同時滿足兩種以上的頻譜特徵,可以進一步
為目標語者的語音,音色及語調改變,但語音內容不變。 提高轉換後語音的音質和與目標語者的相似度,發表在
我們在 2016 年底首度將變分式自動編碼器 (variational ISCSLP2018 的論文獲得最佳學生論文獎。2019 年,我們
autoencoder, VAE) 應用到無對齊語料條件下的語音轉換, 將 WaveNet 聲碼器引進 VAE-based VC,以取代傳統聲碼
發 表 在 APSIPA ASC 2016 的 論 文 在 Google Scholar 已 經 器,並提出一個在編碼層中進一步濾除基頻 (fundamental
有 102 次的引用。2017 年,我們提出結合生成式對抗型 frequency, F0) 資訊的方法。整合相關研究成果的期刊論
網路 (generative adversarial network, GAN) 的無對齊語料 文於 2020 年初獲得 IEEE Trans. on ETCI 接受發表。
條件下的 VAE-based VC,發表在 Interspeech2017 的論文
在 Google Scholar 已經有 145 次的引用。2018 年,我們
圖七:基於 VAE 的語音轉換流程。同傳統語音轉換,聲碼器首先將語音波形參數化為聲學特徵,各特徵流分別經過轉換,最後聲碼
器將轉換後的特徵合成語音波形。我們的研究著重在用於頻譜特徵轉換的編碼器 (Eθ) 和解碼器 (GΦ) 的建模與學習。
未來展望 /
本計畫在基礎研究方面,將持續開展永續學習機制與應用,進行方法優化與改善。除了技術開發外,將與
台大醫院進行智慧急診合作,以 AI 技術進行及早安全離部項目之整合,改善急診病人流動及解決壅塞。並
與和信醫院合作醫學影像腫瘤分割之深度學習模型建置:整合鼻咽 / 淋巴腫瘤偵測,及藉由影像分析改進
診療方案。預定也將與微軟新聞研究群展開合作,協助編輯自動化流程。
41
基於鑑別式自動編碼器之語者辨識及語音辨識
自動編碼器 (autoencoder) 常用於無監督學習中的有效 圖六:基於 DcAE 的語音辨識聲學建模。基線系統的工作流 ( 虛
編碼。我們在 2017 年首度提出一個鑑別式自動編碼器 線 ) 由輸入層、編碼器、P 代碼和輸出層組成。基本版 DcAE
(discriminative autoencoder, DcAE),應用在語者辨識, (DcAE-B) 的工作流用實線表示,其關鍵組件多了用於特徵重
其基本原理是在編碼層藉助不同的減損函數將語者相 構的 R 代碼、解碼器和輸出層。 DcAE-U 則進一步在編碼器和
關信息和語者無關的因素分離,使得語者相關表示具 解碼器層之間增加連接。
備更好的鑑別性,進而提高辨識率。2019 年,我們改
良 DcAE 的架構,成功套用在語音辨識開發工具 Kaldi
的 nnet3 設置中的 TDNN 與 TDNN-LSTM 聲學模型架構
中,並將測試在 WSJ 語料的 recipe 公開。成果發表於
Interspeech2019。
基於變分自動編碼器之語音轉換
語音轉換 (voice conversion, VC) 是將來源語者的語音轉換 提出讓模型同時滿足兩種以上的頻譜特徵,可以進一步
為目標語者的語音,音色及語調改變,但語音內容不變。 提高轉換後語音的音質和與目標語者的相似度,發表在
我們在 2016 年底首度將變分式自動編碼器 (variational ISCSLP2018 的論文獲得最佳學生論文獎。2019 年,我們
autoencoder, VAE) 應用到無對齊語料條件下的語音轉換, 將 WaveNet 聲碼器引進 VAE-based VC,以取代傳統聲碼
發 表 在 APSIPA ASC 2016 的 論 文 在 Google Scholar 已 經 器,並提出一個在編碼層中進一步濾除基頻 (fundamental
有 102 次的引用。2017 年,我們提出結合生成式對抗型 frequency, F0) 資訊的方法。整合相關研究成果的期刊論
網路 (generative adversarial network, GAN) 的無對齊語料 文於 2020 年初獲得 IEEE Trans. on ETCI 接受發表。
條件下的 VAE-based VC,發表在 Interspeech2017 的論文
在 Google Scholar 已經有 145 次的引用。2018 年,我們
圖七:基於 VAE 的語音轉換流程。同傳統語音轉換,聲碼器首先將語音波形參數化為聲學特徵,各特徵流分別經過轉換,最後聲碼
器將轉換後的特徵合成語音波形。我們的研究著重在用於頻譜特徵轉換的編碼器 (Eθ) 和解碼器 (GΦ) 的建模與學習。
未來展望 /
本計畫在基礎研究方面,將持續開展永續學習機制與應用,進行方法優化與改善。除了技術開發外,將與
台大醫院進行智慧急診合作,以 AI 技術進行及早安全離部項目之整合,改善急診病人流動及解決壅塞。並
與和信醫院合作醫學影像腫瘤分割之深度學習模型建置:整合鼻咽 / 淋巴腫瘤偵測,及藉由影像分析改進
診療方案。預定也將與微軟新聞研究群展開合作,協助編輯自動化流程。
41