Our proposed system can be divided into three elements: audio analysis, motion generation, and real-time synchronization. Audio analysis primarily involves automatic music transcription, melody detection, and musical instrument recognition. In the past, due to the diversity of signal characteristics and data labels, it was difficult to establish a systematic solution for automatic music analysis. Nowadays, deep learning-based systems that simultaneously detect multiple pitch, timing, and instrument types have become possible due to the development of neural networks (NN) in multi-task learning (MTL) approaches. Moreover, we can now superimpose different types of signal representations, allowing convolution kernels in NN to automatically select desired features. Consequently, the training model exhibits enhanced robustness, achieves transposition-invariance, and suppresses the challenging overtone errors usually generated in audio processing. More specifically, our proposed method simplifies the issue of musical transcription into semantic segmentation in computer vision. Our U-Net-based architecture considers convolution kernels via attention or dilation mechanisms to simultaneously process objects of different sizes, such as to identify both short and long musical notes.
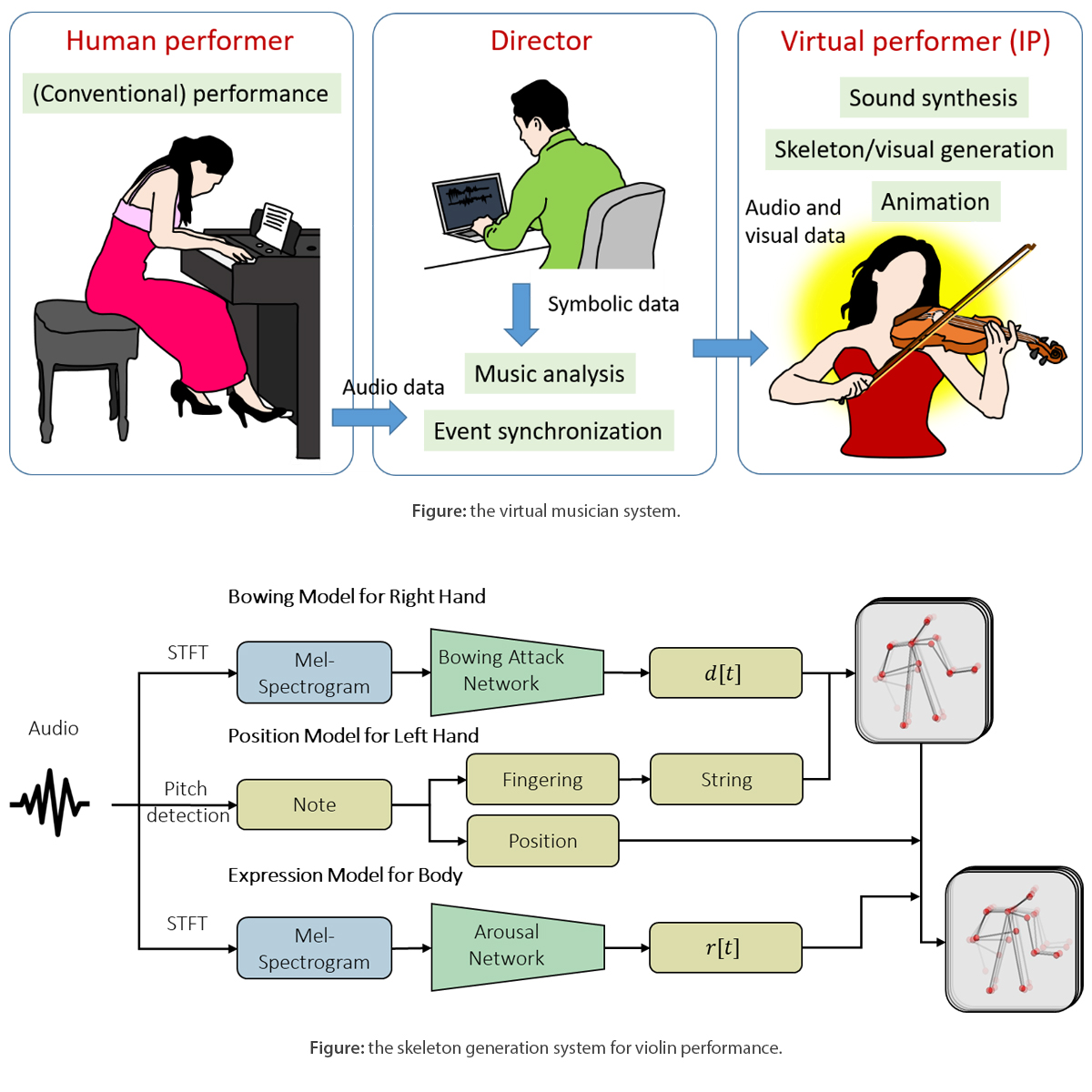
To generate animated body movement, we have achieved preliminary results based on the motion of a violin player. Using a recording of a violin solo as the input signal, we automatically generate coordinate values of the body joints for a virtual violinist. Long-term body rhythms can also be determined by our music emotion recognition model. Instead of employing an end-to-end NN, we are focusing on more interpretable and controllable body movement generation methods. Our proposed model consists of a bowing model for the right hand, a fingering (position) model for the left hand, and a musical emotion (expression) model for the upper body. The bowing model has been designed with an audio-based attack detection network, whereas the fingering model computes left-hand position from music pitch. From this information, patterns for the generated skeleton can be determined. In terms of music emotion recognition, since periodic head tilt and upper body motion tend to follow the rhythm and music type, we incorporate rhythm tracking from the audio model and an emotion predictor model to control those aspects of body motion. These same principles can be applied to other kinds of stringed instruments. We are still tackling the problem of generating body movements solely from audio content, but there are many possibilities for future development.
For real-time synchronization, our proposed system incorporates three elements, i.e., a music tracker, a music detector, and a position estimator. The music tracker includes online dynamic time-warping (ODTW) algorithms working across multiple threads. Each thread uses ODTW to estimate the current performance speed of the live music performance. Estimated values across threads are averaged to obtain a stable and accurate estimate of performance speed. Relative tempo values are obtained by comparing the live performance with a reference performance recording. The function of the music detector is to automatically detect when the music starts, meaning that there is no need to manually launch the real-time synchronization mechanism. Finally, since music exhibits many repetitive segments, our position estimation mechanism allows us to simultaneously track the positions that the musician is currently playing. Combining these three elements, we can immediately align the position of a live performance to a reference recording, allowing a program director to design responsive events based on that information. We have applied this system to music visualization, automatic accompaniment/ensemble, and generation of automatic body movements for a virtual musician.
Our system has been utilized for several live performances, including the Sound and Sense concert (in cooperation with the Pace Culture and Education Foundation, performed in the National Concert Hall), the opening ceremony of the NTHU AI Orchestra (in collaboration with the NTHU AI Orchestra), Whispers in the Night (in collaboration with flutist Sophia Lin, performed in the Weiwuying Auditorium), and Sound and Shape (in collaboration with Koko Lab. Inc., performed at Wetland Venue). These concerts were held not only to test our technology, but also to facilitate in-depth conversation among music producers, performers, and music technology developers, with the view to introducing new-age music technology to the multimedia industry.