Principal Investigators
Group Profile
The Computer Systems Lab was established in 2009. Its primary research areas include multicore systems, virtualization, system software for cloud computing and related applications, and storage designs for embedded systems.1. Auto-parallelism with Dynamic Binary Translation
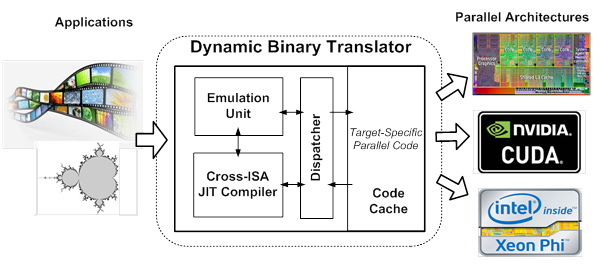
Parallelization is critical for multicore computing and cloud computing. Hardware manufacturers have adopted many distinct strategies to improve parallelism in microprocessor design. These strategies include multi-cores, many-cores, GPU, GPGPU, and SIMD (single instruction, multiple data), among others. However, these parallel architectures have very different parallel execution models and several issues arise when migrating applications from one to another: (1) application developers have to rewrite programs based on the target parallel model, increasing time to market; (2) legacy applications become under-optimized due to under-utilization of parallelism in the target hardware, significantly diminishing potential performance gain; and (3) execution migration among heterogeneous architectures is difficult. To overcome these problems, we developed an efficient and retargetable dynamic binary translator (DBT) to transparently transform application binaries among different parallel execution models. In our current work, the DBT dynamically transforms binaries of short-SIMD loops to equivalent long-SIMD ones, thereby exploiting the wider SIMD lanes of the hosts. We have shown that the SIMD transformation from ARM NEON to x86 AVX2 can improve performance by 45% for a collection of applications, while doubling the parallelism factor. We plan to extend the DBT system by supporting more parallel architectures and execution models. Furthermore, we will re-optimize legacy codes by exploiting enhanced ISA features provided by new parallel architectures.
2. Design and Implementation of a Cloud Gaming System
Cloud gaming systems render game scenes on cloud servers and stream the encoded scenes to thin clients over the Internet. The thin clients then send user inputs, from joysticks, keyboards, and mice, back to the cloud servers. With cloud gaming systems, users can: (i) avoid upgrading their computers for the latest games, (ii) play the same games using thin clients on different platforms, such as PCs, laptops, tablets, and smartphones, and (iii) play more games due to reduced hardware/software costs. Game developers may: (i) support more platforms, (ii) avoid hardware/software incompatibility issues, and (iii) increase net revenues. Therefore, cloud gaming systems have attracted attention from users, game developers, and service providers. We have developed an open cloud gaming system, GamingAnywhere, which can be used by cloud gaming developers, cloud service providers, and system researchers for setting up a complete cloud gaming testbed. GamingAnywhere is the first open cloud gaming testbed to be reported, and we conduct extensive testing to quantify its performance and overhead. We derive the optimal system parameters, which allows users to install and try out GamingAnywhere on their own servers. We expect that cloud game developers, cloud service providers, system researchers, and individual users will use GamingAnywhere to set up complete cloud gaming testbeds for different purposes. We firmly believe that the release of GamingAnywhere will stimulate more research innovations on cloud gaming systems, or multimedia streaming applications in general.
3. Efficient and Scalable MapReduce Platform
MapReduce is a programming model proposed by Google for processing and generating large data sets on clouds with a parallel, distributed algorithm. An implementation of the MapReduce framework was utilized by an Apache open-source project named Hadoop. The Hadoop MapReduce framework was very successful and widely adopted in the processing of large datasets. However, our experience on suffix array construction with Hadoop showed that excessive disk usage and access may occur. Therefore, the performance is degraded and the scale of the application is limited. Expansive MapReduce (EMR) applications, such as suffix array construction, are a group of applications that have performance and scalability issues with Hadoop. Our first approach is to instruct in-memory data stores to keep the input data of MapReduce jobs such that the volume of partially duplicated data is minimized. The second approach is to pass intermediate key/index pairs to reducers if the size of a key/index pair is much smaller than the size of a key/value pair. The intermediate values can later be retrieved from in-memory data stores by reducers. This may greatly reduce the disk usage and access in the shuffle and sorting phase. Our third approach is to optimize the response of in-memory data stores, so as to improve the overall performance. With these approaches, we shall propose a MapReduce framework for EMR applications, which will be validated using suffix array construction as our testbed.
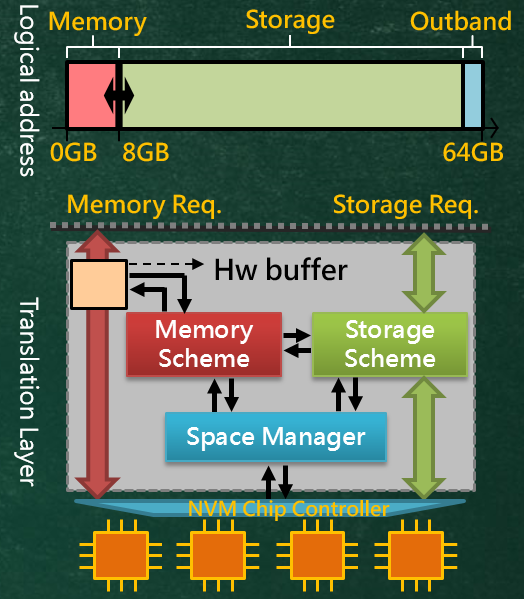
4. Non-volatile Memory as Main Memory and Storage
Because data-intensive applications are increasingly being run on computer systems, it has become critically important to improve I/O efficiency. Responding to low access performance of existing storage devices by enlarging DRAM capacity to support more data-intensive applications introduces more energy consumption, which is a major concern in system design. Thus, a new opportunity for non-volatile memory (NVM) has presented itself. We propose to adopt NVM as both main memory and storage. Replacing DRAM with NVM will reduce energy consumption of main memory, and replacing disk drives will enhance I/O performance because of NVMs superior byte-addressability, non-volatility, capacity for scalability, and high access performance. To achieve this goal, we propose an NVM translation layer for the NVM controller, which considers how the main memory is used by the operating system together with the access patterns between main memory and storage. In this translation layer, we resolve the endurance issue by allocating young NVM cells from the whole NVM space for main memory uses, and switch the NVM cells from the storage space to the main memory space in order to enhance performance during loading/ storing data between mainmemory buffer and storage. In the future, we will continue to tackle these efficiency issues from the perspective of the operating system by rethinking the memory management and file system design to optimize the benefits of using NVM as both main memory and storage.