Principal Investigators
Group Profile
Data of various types (e.g., sensor data, transactions, multimedia, social network, Web browsing log, etc.) are being generated at an ever increasing rate. As computer hardware and networks are abundant and inexpensive, the timing has never been better to explore possible means of utilizing such data to develop new technologies that solve difficult problems or to explore applications that were previously impossible. The Data Management and Information Discovery Group was formed with the main objectives of initiating innovative research and strengthening scientific and technological excellence in: (1) effective collection, representation, storage, processing, and analyzing of massive data; and (2) exploring data mining and machine learning technologies which may efficiently and effectively uncover valuable knowledge within various types of data. Currently, research from this group focuses on the following topics: (1) Social Influences and Query Processing for Social Networks; (2) Modeling and Prediction of Real-Time Bidding in Online Display Advertising; (3) Deep Learning for Urban Air Pollution Prediction; (4) Indexing, Data Mining and Management for Non-Volatile Main Memory. The followings are the introduction of the problems we have been working on.1. Social Influences and Query Processing for Social Networks
Our research on social networks focuses on the development of efficient social group queries and social influence. For location-based social networks, we formulate a Social-Spatial Group Query with a new index structure that can efficiently find spatially close-by friends with tight social relations and corresponding rally points at their available time slots. In addition to the spatial and temporal dimensions, we explore group search that addresses user preference. The proposed randomized algorithm has a guaranteed performance bound, which can be exploited in Online-To-Offline social applications and group coupon services. For professional social networks, we propose a new socio-spatial query to form a strong task group that addresses the group distance, professional skills of group members, and social rapport in the group. We prove that the problem is inapproximable within any ratio, but an approximation algorithm exists when a small error bound is permitted. Recently, we considered social presence theory in social psychology to formulate a new problem for organizing friend-making activities via online social networks. For this we designed a 3-approximation algorithm.
In addition to social queries, we explore influence diffusion on a specific target. As such, we find the optimal group of intermediate nodes that may change a target´s decision. We also deploy this distributed computation in mobile social networks to find optimal solutions. Moreover, we incorporate frequent pattern mining and product bundles for viral marketing of multiple correlated products. We present a new Social Item Graph that captures both social influence and frequent patterns in the form of hyperedges in a hypergraph. We have designed an approximation algorithm and a new index structure based on FP-Tree. In another project, we have found that mining online social behavior provides an opportunity to actively identify social network mental disorders (SNMDs) at an early stage. We propose a machine learning framework, namely, Social Network Mental Disorder Detection (SNMDD) and a new SNMD-based Tensor Model to accurately identify potential cases of SNMDs. Our results show that SNMDD is a promising tool for identifying users with potential SNMDs. For group therapy, we have formulated the Member Selection for Online Support Group (MSSG) to maximize the similarity of the symptoms between all selected members, while ensuring that any two members are unacquainted to each other. We proved that MSSG is NPHard and inapproximate within any ratio. Also, we designed a 3-approximation algorithm with a guaranteed error bound.
2. Modeling and Prediction for Real-Time Bidding on Online Display Advertising
Online display advertising is now programmatic. The ad impression displayed for each website visitor may be different and is dynamically decided by a mechanism called Real-Time Bidding (RTB), which brokers interactions between publishers and advertisers. In the RTB environment, advertisers rely heavily on having a good prediction model for ad click-through-rates to effectively and efficiently target potential customers and offer a reasonable bids. We aim to design an appropriate learning method from historical bidding data with incomplete labels so that advertisers can have an effective model to accurately predict the ad click-through rates and find a good bidding strategy under budgetary constraints.
3. Deep Learning for Urban Air Pollution Prediction
Air pollution prediction and source identification have become critical issues in environmental protection, human health, economics and even politics. In the past three years, there have been many studies trying to predict fine grained air pollution using various techniques, including neural networks, various machine learning methods, graph theory, statistics, meteorological models, or a combination thereof. However, most studies fail to make accurate predictions for an urban areas, because the area itself produces pollution as well as receiving pollution from remote sources. In this research, we consider the characteristics of urban areas and design a deep learning architecture composed of various neural networks, including autoencoders, layers of experts, LSTMs (Long Short Term Memory), RBNs (Restricted Boltzmann machine). Currently, we are working on incorporating meteorological models to predict transport of remote pollutants in order to further improve predictions..
4. Indexing, Data Mining and Management for Non-Volatile Main Memory
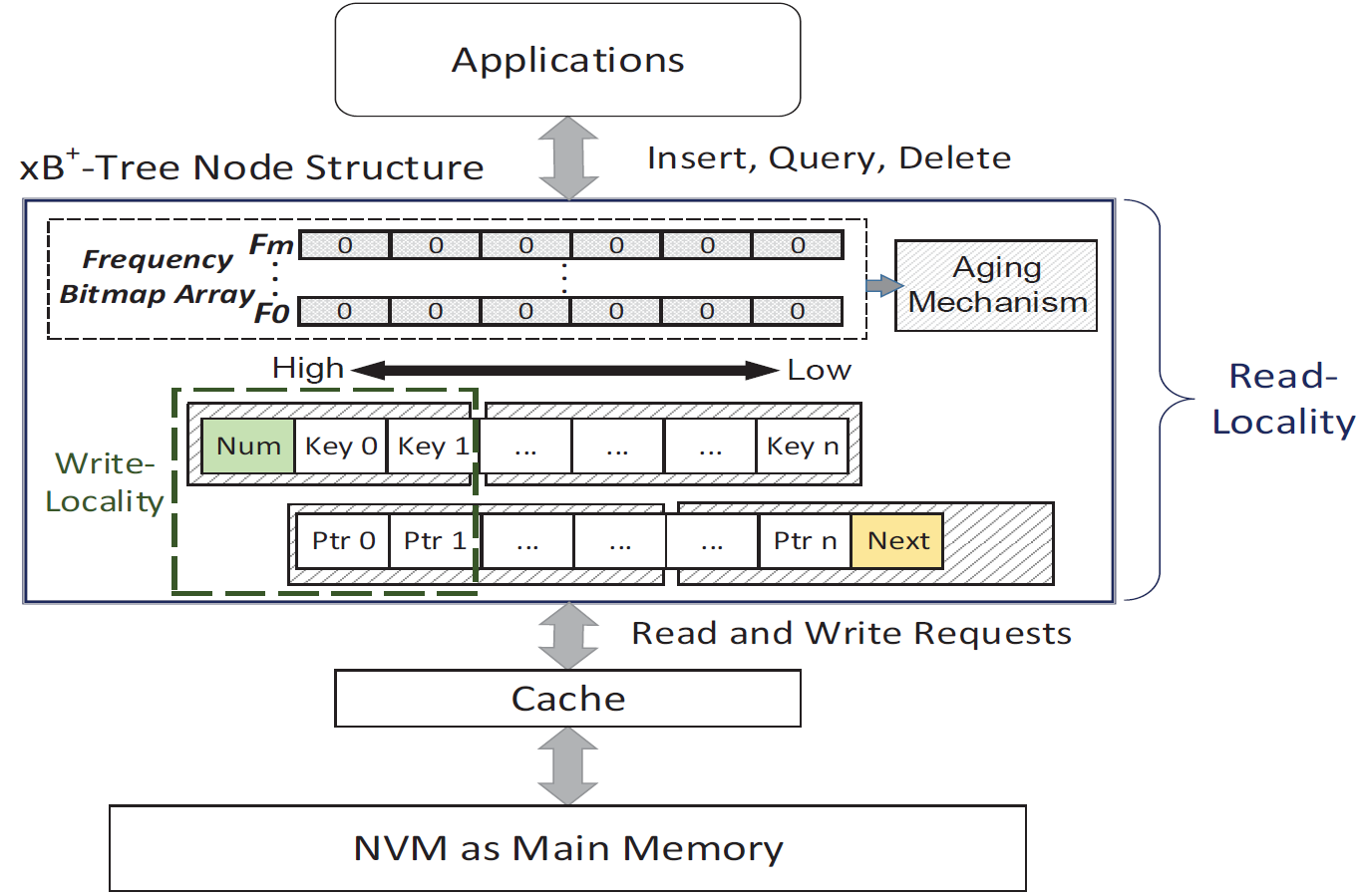
Non-volatile memory (NVM) has been instrumental in the evolution of next-generation memory architecture and has become a popular alternative to replace DRAM as the main memory of domain-specific computing systems. In addition to its non-volatility, NVM has very low idle power (or leakage power) and higher cell density for capacity scaling. However, compared to DRAM, NVM usually has longer write latency and write energy. Our research focus is to propose new designs that improve the access performance of NVM-based main memory architecture and accommodate special access patterns found in many popular internet of things (IoT) and in-memory database applications. For example, we propose a new index design, called access-pattern-aware cacheline- based tree (xB+- tree), to improve the access performance of NVM-based main memory architecture by considering the cache-line-based access behavior between CPU/ processor and main memory. This design will keep frequently accessed key-value pairs or indexes in the minimal number of cache lines and aggregate consecutively queried data items in the same cache line, minimizing the number of accesses to NVM main memory. We implemented and evaluated the effectiveness of the design on the Gem5 simulator. In the future, we will continue to study index designs with NVM main memory for big data applications and inmemory computing systems. For example, in big data applications, data may be frequently generated and rarely deleted, with only a small portion of data items being frequently queried. Thus, we must devise methods to increase the cache hit ratio and decrease the cache miss ratio by proactively and smartly placing data items into different cache lines, according to the special access patterns of each big data application. In addition to performance, the endurance of NVM main memory will also be investigated.
New NVMs have large capacity, low cost and are energy efficient. These technologies are good candidates to replace traditional DRAM and enable in-memory computing. We aim to revisit data mining algorithms, such as frequent pattern mining, and re-design these algorithms to be NVM friendly by using more read operations than write operations. In this way, we can leverage the advantages of NVM for in-memory data mining while minimizing the memory access latency and enhancing its endurance.