Principal Investigators
Group Profile
Multimedia technology is considered to be one of the three most promising industries of the twenty-first century, along with biotechnology and nanotechnology. Over the past two decades, we have witnessed how multimedia technology can influence various aspects of our daily life. Its wide spectrum of applications presents a constant challenge to advance a broad range of multimedia techniques, including those related to music, videos, images, text and 3D animation.The main research interests of individual Multimedia Technology Group members include multimedia signal processing, computer vision and machine learning. In addition to these individual research interests, joint research activity in this group can be best characterized by its two ongoing major projects: (A) Integration of Video and Audio Intelligence for Multimedia Applications and (B) Deep Learning for Multimedia Information Processing.
A. Integration of Video and Audio Intelligence for Multimedia Applications
This project explores new multimedia techniques and applications that require the fusion of video and audio intelligence. With the prevalence of mobile devices, people can now easily film a live concert and create video clips of performances. Popular websites such as YouTube or Vimeo have further enabled this phenomenon as data sharing becomes easy. Videos of this kind, recorded by audiences at different locations of the scene, provide those who could not attend the event the opportunity to enjoy the performance. However, the viewing experience is usually degraded because the multiple source videos are captured without coordination, inevitably leading to incompleteness or redundancy. To amplify the pleasure of the viewing/ listening experience, effectively fusing videos with a smooth “decoration” process, generating a single, near-professional audio/visual stream would be highly desirable.
Video mashup, an emerging research topic in multimedia, can satisfy these requirements. A successful mashup process should consider all videos captured at different locations and convert them into a complete, nonoverlapping, seamless, and high-quality product. To successfully conduct a concert video mashup process, we propose to address the following issues: (1) To make the mashup outcome as professional as possible, we propose to integrate the rules defined in the language of film; (2) To navigate the visual order of different video clips, we have to solve the causality problem of the visual component; (3) In addition to the visual component, alignment of multiple audio sequences should also be carefully addressed. For example, automatic soundtrack suggestions for usergenerated video (UGV) is a challenging but desirable task. A major reason for the challenge is that the distance between video and music cannot be measured directly. Motivated by recent developments in affective computing of multimedia signals, we map low-level acoustic and visual features into an emotional space, and match these two modalities therein. Our research simultaneously tackles video editing and soundtrack recommendation. The correlation among music, video, and semantic annotations such as emotion will be actively explored and modeled. A music-accompanied video that is composed in this way is attractive, since the perception of emotion naturally occurs during video watching and music listening.
B. Deep Learning for Multimedia Information Processing
Owing to its effectiveness in solving various challenging tasks, deep learning-related research has attracted great attention in recent years. In the field of Multimedia Information Processing, deep learning has revealed new opportunities for solving both conventional and modern research problems. During the upcoming few years, we aim to rigorously re-formulate or better solve emergent multimedia-related problems using deep learning. These efforts are highlighted by the following three collaborative projects.
1. Visual information processing:
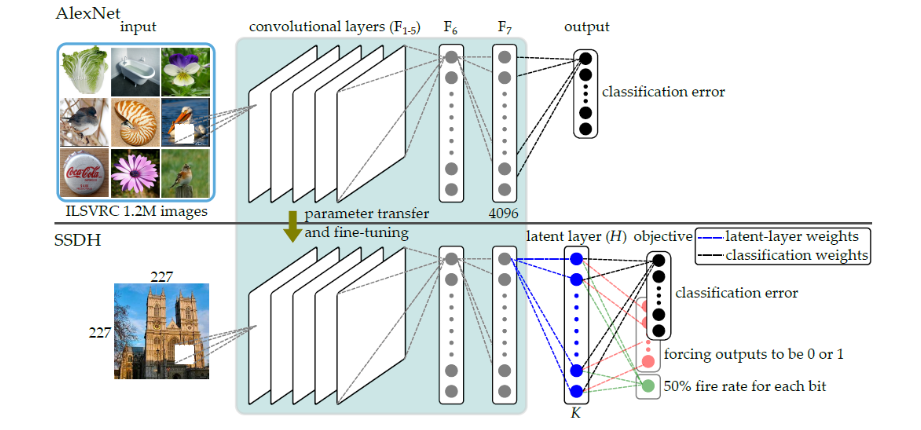
based on the recent progress¬ with GPUs and large-scale databases, the deep convolution network (CNN) has received extensive attention. Deep CNN can learn rich feature representations from images, and performs impressively on image classification and object detection tasks. While most deep learning methods are designed for classification purposes, they are not necessarily suitable for search or retrieval of relevant images. Our study focuses on the development of new deep learning methods for image or video retrieval. We address two main issues, retrieval efficiency and accuracy. To improve the retrieval efficiency of deep networks, we proposed a simple yet effective supervised deep hash approach that constructs binary hash codes from labeled data for large-scale image searching. Our approach, dubbed supervised semantics-preserving deep hashing (SSDH), constructs hash functions as a latent layer in a deep network and the binary codes are learned by minimizing an objective function defined over classification error and other desirable hash codes properties. The work has been accepted by IEEE TPAMI in 2017 (with a preliminary version in CVPRW, 2015). To improve retrieval accuracy, we introduce and idea called cross-batch reference (CBR), which can enhance the training of CNNs. The results have been published as a long paper in ACM MM, 2016. Our ongoing research also includes multi-modal depth learning for audiovisual speech enhancement and user identification. In the future, we will develop effective approaches to analyze characters in a movie and mine their relationships by combining image and natural-language information.
2. Crowd behavior analysis:
A crowd can remain motionless or move with respect to time. When a crowd moves, it moves in a non-rigid manner, or may form sub-groups of people. Therefore, effective analysis of crowd behavior is a nontrivial task. We aim to propose heuristic definitions for characterizing a crowd. Based on these criteria, we would propose various deep-learning modules to construct a complete framework for analyzing crowd behaviors, including subgroup detection, sub-group merging, abnormal behavior detection and other traits.
3. Music information retrieval:
Most descriptions of music apply at multiple granularities, since music signals are constructed with multiple instruments, hierarchical meter structure and mixed genres. The problem of music information retrieval could therefore be considered in deep neural networks (DNNs) with a multi-task learning (MTL) setting. MTL-based DNNs have previously been found to be applicable in musical chord recognition. These networks can recognize a chord and root note in parallel, suggesting that the technology may be extendable to other musical information as well.