研究人員
研究群介紹
多媒體技術與生物科技及奈米科技,被公認為是二十一世紀最具影響力的科技產業。在過去二十多年來,我們已見證了多媒體相關技術對於日常生活中的多層面影響與改善。 多媒體科技的應用極廣,促使了包含視訊、音樂、三維動畫、影像、聲音等技術上的進步,並衍生出更多科學研究的持續挑戰。多媒體技術實驗室成員的主要研究方向,包括多媒體訊號處理、電腦視覺和機器學習。每位研究人員除了專注於個 人有興趣的研究專題外,也透過共同參與大型計劃,以期在重要研究議題上能有關鍵性突破。目前本實驗室正在執行的大型合作計畫共有兩項,分別是(1)結合視訊及音訊之多媒體應用;(2)深度學習於多媒體資料處理之研發及應用。茲分述如下
(1) 結合視訊及音訊之多媒體應用:
我們的研究重點,在於開發結合視訊及音訊特徵的多媒體技術和應用。更詳細地來說,我們探討下述應用:鑑於手 持式裝置越來越流行,很多年輕人可以輕易在演唱會現場錄製一段現場演唱視訊片段,然後在回家後將之上傳到 YouTube 或者Vimeo 與朋友共享。觀賞業餘觀眾以手持裝置在不同位置所錄得的視訊片段,感覺往往非常吃力且不愉快。原因是眾多觀眾在錄影時並未事先協調好誰先錄, 誰取那一段來錄等細節問題。因此,放在YouTube 上面的 眾多視訊片段難免重複播放或短少某些片段。為了能讓未到演唱會現場的觀眾有一愉快的「再次欣賞」機會,吾人 需要一個有系統的「整合」演算法則。通常,吾人稱此整合為「視訊雜湊」(Video mashup)。
演唱會視訊雜湊會面臨的挑戰,主要有三方面:(1)通常要完成一個有水準的視訊雜湊,必須遵守導演的編導語言 (language of film)。通常,導演會透過轉換鏡頭,用距離長短、拍攝角度及特寫鏡頭等方式來呈現其藝術、情感及技巧。如何自動「解讀」拍攝距離及角度,是一項艱鉅的挑戰;(2)眾多由不同角度拍攝之視訊片段如何在「視 覺」上找出其先後順序,並有效加以銜接,也是一挑戰;(3)演唱會視訊片段不僅只有視覺的部分,聲音的部分如何判定其先後順序及判斷其音質好壞,也是一項挑戰。例如, 如何自動向用戶生成的視頻建議音軌( 亦即幫用戶拍攝的影 片自動配樂) 是一個具有挑戰性但值得嚮往的任務,最難的部分是視頻和音樂之間的距離不能直接測量。隨著最近多 媒體信號的情感計算的發展,我們將低階的聲學和視覺特徵映射到情感空間中,並且在那裡匹配這兩種模態。我們的研究同時處理視頻編輯和音軌推薦問題。音樂,視頻和 諸如情感的語義註釋之間的相關性將被積極地探索和建模。我們相信以這種方式組成的音樂影片是吸引人的,因為情感的感知自然發生在視頻觀看和音樂收聽期間。
(2) 壓縮感知及稀疏表達法:
深度學習在近幾年是一火紅的研究方向。Alpha Go 打敗韓國世界棋王更突顯了這個領域之可行性及未來性。多媒體資料處理領域有許多老問題及新興議題。深度學習已被證明在Pattern Matching 上面極具效用,既存的多媒體資料處理議題有一些原本在辨識上效果並不好,我們打算引入深度學習來處理一些既存的議題,希望能大大提升原本不易突破的瓶頸。在新研究議題方面,我們打算針對較困難,與視訊相關的議題進行研發。
在未來數年,我們打算從事以下深度學習應用於多媒體資料處理的相關議題:
1. 視覺資訊處理:
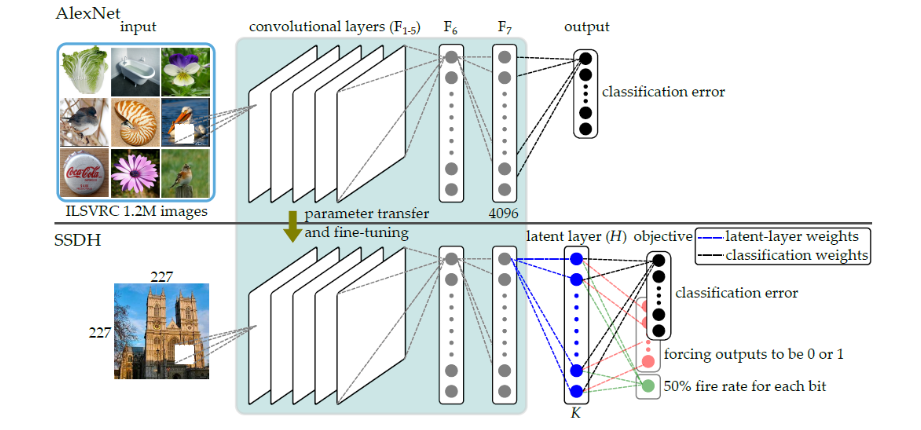
基於最近大型資料庫與GPU 的進展,深層卷積網路獲得了廣泛的重視。其可學習豐富的特徵表示,並在影像分類與物品偵測上展現良好效果。然而目前大部分的深度學習方法都是針對分類問題作設計,擅長於標籤判斷的工作,但不一定適合於相關例(relevant instance)的搜尋與檢索。 我們的研究著重於開發新的深度學習方法,以利於影像或視訊檢索。考量深度學習在檢索方面仍存在兩大問題。其一是所訓練特徵之存取效率不彰,其二是特徵比對的準確性受限。由於檢索所需之空間龐大,常需以二元(binary) 或雜湊(hash) 碼的方式儲存以降低所需空間。而深層網路訓練的特徵大部分為多維的實數向量,因此如何改造深層網路,使其具備學習高效率的二元特徵碼的能力,是亟需探討的問題。此外,目前的特徵通常以分類損失函數 (loss function) 加以訓練而成,所習之特徵空間具備異類分開的特性,雖適合於分類,但不一定適用於檢索。針對以上問題,我們發展了新的的方法。在檢索效率方面,我們在2015年提出一個以潛在層(latent layer) 學習二元特徵碼的方法,能夠在不影響分類準確率的方式下,強化檢索的速度,這是 目前深層學習二元雜湊碼的代表方法之一,發表於 CVPRW 2015,完整成果並於2017 年被期刊IEEE TPAMI 接受。另一方面,我們也將分類損失函數改良為檢索損失函數,並發展跨批次的學習方法,以訓練出同時具備異類與同類(或相關)樣本集中之特徵空間,讓檢索結果更準確,此成果發表於國際會議ACM MM 2016 之長篇論文。
2. 群眾行為分析:
群眾行為分析牽涉到許多人在時間軸上的位置變化,要利用深度學習網路原本慣用的架構去分析群眾並非易事。我們打算設計適當的深層網路去分析動態的群眾行為。
3. 音樂資訊檢索:
音樂訊號往往包涵多種樂器、階層式的拍號結構和混雜的曲風,通常皆以多重標記描述。因此,音樂資訊檢索問題可以利用多重任務學習架構之下的深度神經網路來處理。此方法已經被證實在音樂和弦辨識的問題上(即同時處理和弦名稱和根音名稱)有其實用性。
此外,我們正在進行的研究還包括用於視聽語音增強和用戶識別的多模式深度學習。 未來我們將開發於視訊中結合影像與自然語言,挖掘出人物相關資訊的方法,以利於更高階的語意檢索。