基於貝氏資訊基準之分割且克服的語者分段方法
IEEE Transactions on Audio, Speech, and Language Processing 18 (2010): 141-157.
鄭士賢、 王新民、 傅心家
- 中央研究院資訊科學研究所
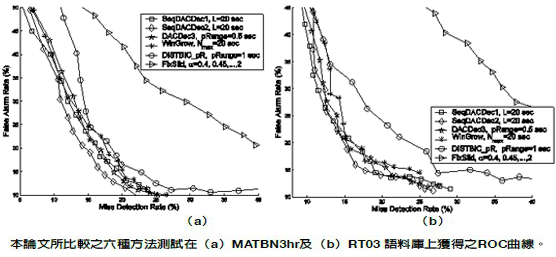
語者(音訊)分段的目的是偵測一段聲音訊號中的語者(聲學特性)轉換點。針對這個問題,過去十年間,語音處理研究領域的學者花費很大的心力,主要的原因是這項技術在語音及音訊處理有許多應用,例如音訊分類、音訊錄音自動轉寫、語者追蹤及語者自動分段標記等。本論文提出三種基於貝氏資訊基準(Bayesian Information Criterion, BIC)之分割且克服(divide-and-conquer)的分段方法,分別是SeqDACDec1、SeqDACDec2及DACDec3。新方法採遞迴方式將一分析窗在最可能的語者轉換點切割成兩個子分析窗,直到處理完所有可能的轉換點,再反方向檢測這些切割點兩端音段的BIC差值(ΔBIC),以決定將該切割點記為語者轉換點或是將該相鄰兩音段合併。我們將新方法與三種常用的分段法進行比較,包括Chen and Gopalakrishnan提出的分析窗增長法(window-growing-based approach,WinGrow)、Siegler等人提出的固定長度 分析窗滑動法(fixed-size sliding windowapproach, FixSlid)及Delacourt and Wellekens提出的DISTBIC法(DISTBIC_pR)。除了分析各方法的計算複雜度,我們也在兩套廣播新聞資料庫進行語者分段實驗,結果顯示,新方法無論在處理速度還是分段正確率都優於所比較的三種常用方法。此外,我們將所有測試方法應用在語者分段標記,實驗結果顯示較佳的語者分段法確實可以提升語者分段標記的正確率。
基於群依特徵選取的複雜資料分群
Lecture Notes in Computer Science 6316 (2010): 84-97.
林彥宇、 劉庭祿、 傅楸善
- 中央研究院資訊科學研究所
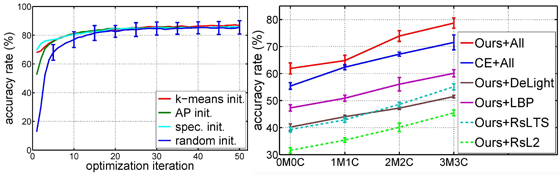
在本論文中,我們提出了一個能有效地偵測複雜資料中的一致性結構之分群演算法,並展現它在電腦視覺應用上的效能。在這裡我們稱一個資料集合為複雜,是指它的資料點間,在屬性上具有高度的變異性,因此若只用單一特徵子來表示,往往不能準確地反應資料類別間的真實關係。我們的方法假設資料的多種特徵表示已在事先計算與萃取完成,而所提出的分群演算法就是利用這些特徵表示來還原資料的群結構。為了達成這個目標,我們將每一群的資料連結至一個分類器,這個分類器則使用提昇演算法來實現多核學習,而它的功用就是跨越不同特徵空間進行最佳特徵選取來分開屬於與不屬於該群的資料。具體來說,我們把這些具高度相關性的群分類器之訓練,融入在資料分群的過程中,並將所有的任務以一個有限制的最佳化問題來呈現。在迴圈式的最佳化過程中,群的真實結構將逐漸地藉由這些群分類器而顯露出來,另一方面,群分類器的效能亦將因資料類別的正確率提高而逐步地增強。
Efficient Simulation of the Spatial Transmission Dynamics of Influenza
PLoS ONE 2010, 5, e13292
Meng-Tsung Tsai, Tsurng-Chen Chern, Jen-Hsiang Chuang, Chih-Wen Hsueh, Hsu-Sung Kuo, Churn-Jung Liau, Steven Riley, Bing-Jie Shen, Chih-Hao Shen, Da-Wei Wang, and *Tsan-Sheng Hsu
- 中央研究院資訊科學研究所
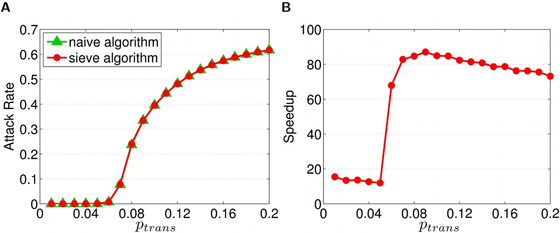
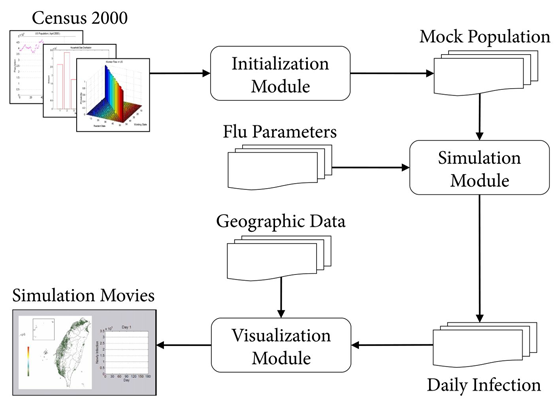
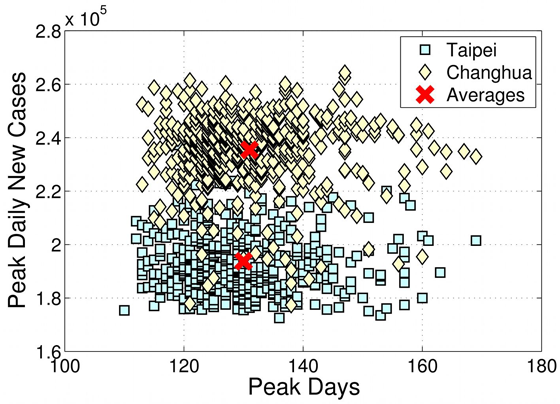
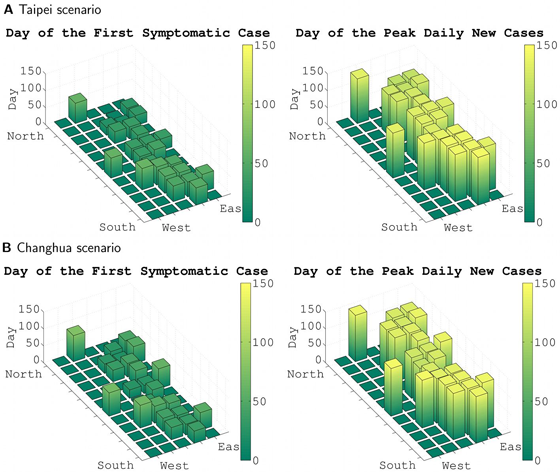
As large spatially resolved data sets are constructed to investigate the spreading patterns of pandemic influenza, the need for efficient simulation code becomes clear. Here, we present a significant improvement to the efficiency of an individual based stochastic disease simulation framework commonly used in previous studies. We quantify the performance of the revised algorithm and present an alternative parameterization of the model in terms of the basic reproductive number. We apply the model to the population of Taiwan and demonstrate how the location of the initial seed can influence spatial incidence profiles of the epidemic. The ability to perform efficient simulation allows us to run a batch of simulations and take account of their average in real time. The averaged data are stable and can be used to differentiate spreading patterns that are not readily seen by only conducting a few runs.